DALL·E 1#
Blog post: https://openai.com/blog/dall-e/
Code: openai/dall-e
Model: Not available
Alternative code (PyTorch): lucidrains/DALLE-pytorch
Alternative code (JAX/Flax): borisdayma/dalle-mini
The DALL·E 1 paper proposes a simple approach for text-to-image generation using a transformer model that autoregressively models text and image tokens as a single stream of data. Unlike traditional approaches that require complex architectures and auxiliary losses, DALL·E 1’s approach relies on data and scale to be competitive with previous domain-specific models in zero-shot evaluations. This approach eliminates the need for training on a fixed dataset and enables generating images from previously unseen text descriptions.

Fig. 143 DALL·E 1#
DALL·E’s initial version is a transformer decoder that generates a 256×256 image from text input and an optional beginning of the image.
Text is encoded by BPE-tokens with a maximum of 256, while images are encoded by special image tokens with 1024 options, using a discrete variational autoencoder (dVAE).
The dVAE encodes 256×256 images into a grid of 32×32 tokens with an 8192 possible value vocabulary.
Generated images by DALL·E may have blurriness and smoothness due to the loss of high-frequency features and details resulting from the dVAE encoding process.
DALL·E 1 Charateristics#
Controlling Attributes#
Controlling attributes of DALL·E 1 refers to generating images with specific features according to textual input.
The model can control various attributes, such as shape, color, position, style, and composition of objects in the generated image.
To control attributes, the model uses prompts with flexible and open-ended descriptions.
During training, the model learns to associate textual input with specific visual attributes.
The conditioning mechanism enables the model to generalize to new attribute combinations not present in the training data.

Fig. 144 Controlling Attributes#
Drawing Multiple Objects#
DALL·E faces a challenge of controlling multiple objects, their attributes, and spatial relationships simultaneously.
Variable binding is crucial for this task as it associates attributes with specific objects.
DALL·E’s ability to handle variable binding is tested with examples of relative positioning, stacking objects, and controlling multiple attributes.
DALL·E offers some level of controllability but the success rate is dependent on how the caption is phrased.
As more objects are introduced, DALL·E’s success rate sharply decreases.
DALL·E is found to be brittle with respect to rephrasing the caption, and alternative captions often yield no correct interpretations.

Fig. 145 Drawing Multiple Objects#
Visualizing Perspective and Three-Dimensionality#
DALL·E allows for control over the viewpoint of a scene and the 3D style in which a scene is rendered.
DALL·E’s ability to control viewpoint and 3D style is demonstrated with examples of an extreme close-up view of a capybara sitting in a field and a capybara made of voxels sitting in a field.
DALL·E’s ability to repeatedly draw the head of a well-known figure at each angle is tested and found to produce a smooth animation of the rotating head.
DALL·E can apply some types of optical distortions to scenes, as seen with the options “fisheye lens view” and “a spherical panorama.”
DALL·E’s ability to generate reflections is explored.

Fig. 146 Visualizing Perspective and Three-Dimensionality#
Visualizing Internal and External Structure#
DALL·E’s ability to render internal and external structure is explored through cross-sectional views and macro photographs.
The samples from the “extreme close-up view” and “x-ray” style led to further exploration of DALL·E’s capabilities in rendering internal and external structures.
The cross-sectional views and macro photographs highlight DALL·E’s ability to generate images with fine details and textures.

Fig. 147 Visualizing Internal and External Structure#
Inferring Contextual Details#
The task of translating text to images is underspecified, leading to multiple plausible images for a single caption.
DALL·E’s ability to resolve underspecification is explored in cases of changing style, setting, and time; drawing the same object in various situations; and generating an image of an object with specific text written on it.
DALL·E provides access to a subset of 3D rendering engine capabilities through natural language, controlling attributes of a small number of objects, their arrangement, and the location and angle of the scene.
DALL·E can “fill in the blanks” and generate certain details not explicitly stated in the caption, unlike a 3D rendering engine that requires unambiguous and detailed inputs.

Fig. 148 Inferring Contextual Details#
DALL·E 1 Architecture#
The DALL·E 1 architecture includes a large transformer model with 12B parameters.
The model consists of 64 sparse transformer blocks with various attention mechanisms, including classical text-to-text masked attention, image-to-text attention, and image-to-image sparse attention.
All three attention types are merged into a single attention operation.
The model was trained on a dataset of 250M image-text pairs.
VQ-VAE#
VQ-VAE is a type of machine learning model that can be used to learn compressed representations of images or other types of data. It works by first encoding the input data into a set of discrete codes, which are then used to reconstruct the original data. Unlike other types of machine learning models, which use continuous values for their internal representations, VQ-VAE uses discrete values, which can make it more efficient and easier to work with in certain situations.
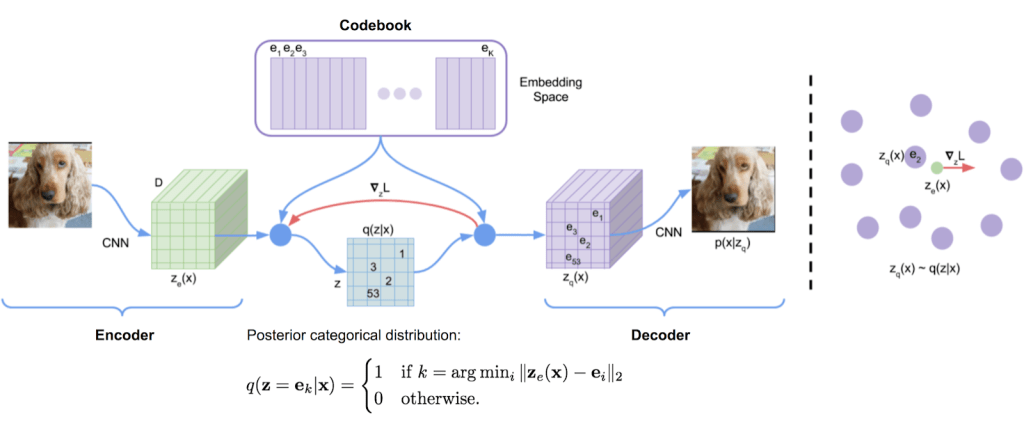
Fig. 149 VQ-VAE#
VQ-VAE is a type of variational autoencoder that uses vector quantization to obtain a discrete latent representation.
This is in contrast to the continuous latent space that other variational autoencoders have.
The objective function of a VQ-VAE, when trained on an image dataset, can be written as:
\(\mathcal{L} = \mathbb{E}_{q(z|x)}[\log p(x|z)] - \beta \cdot D_{KL}[q(z|x) || p(z)]\)
where \(p(x)\) is the data distribution, \(q\) is the approximate posterior over latent variables and \(D_{KL}\) denotes the Kullback-Leibler divergence.
This objective function encourages the model to learn an efficient codebook that minimises reconstruction error while also matching the prior distribution over codes.
A latent space
A latent space is obtained by encoding the input image into the nearest codebook entry. This process is called vector quantization and results in a discrete latent space.
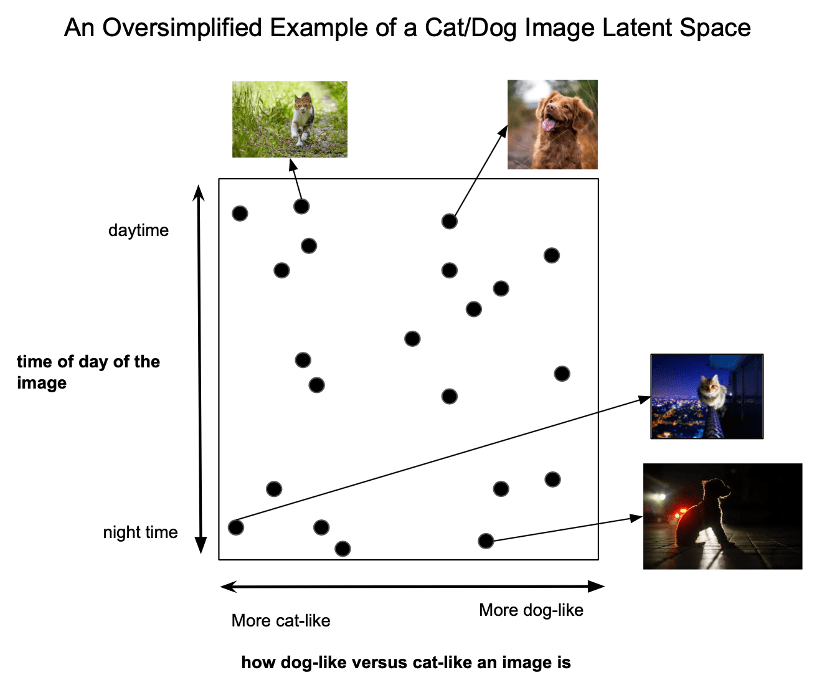
Fig. 150 A latent space#
A latent space is a simplified version of an input image created by a machine learning model.
The process of transforming the input image into the latent space is called encoding.
Vector quantization is a type of encoding that transforms the input image into the nearest codebook entry, resulting in a discrete latent space.
The latent space contains only the most important information from the input image, making it easier to work with and more efficient for the machine learning model.
Autoencoders#
Autoencoder is a type of neural network that learns how to represent input data in a more compact way. It works by trying to predict its own input, so it learns to compress the input data into a smaller set of values that can later be used to reconstruct the original data.
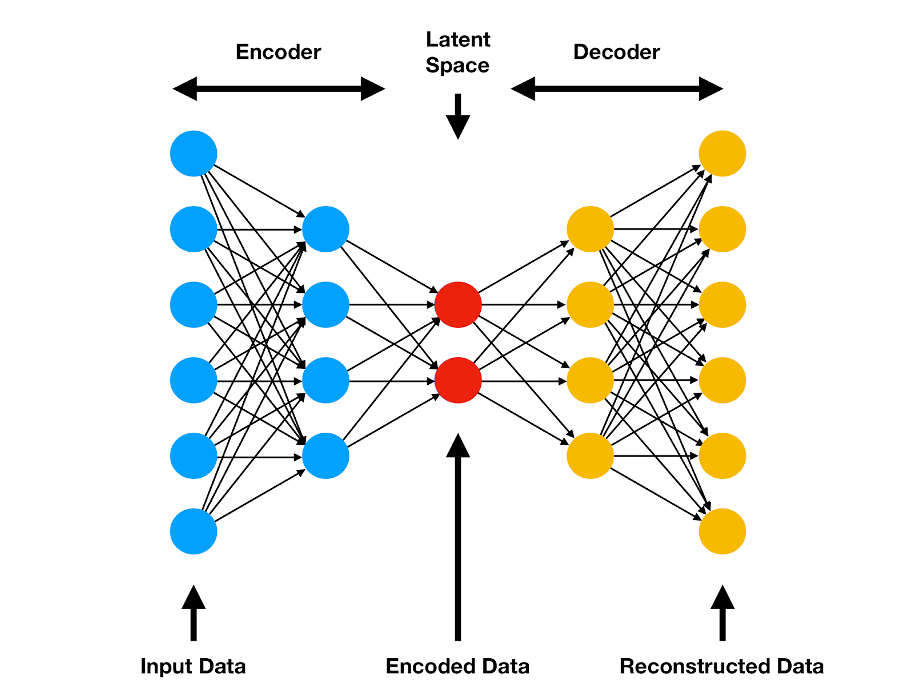
Fig. 151 Autoencoders#
Autoencoder is a neural network that is trained to predict its input.
The objective function of an autoencoder can be written as:
\(\mathcal{L} = \mathbb{E}_{p(x)}[\log p(x|z)]\)
where \(p(x)\) is the data distribution and \(p(x|z)\) is the model distribution.
This objective function encourages the model to learn a latent space that captures the underlying structure of the data.
A VQ-VAE can be seen as a type of autoencoder where the latent space is constrained to be discrete.
Variational Autoencoders (VAE)#
Variational Autoencoders (VAE) are a type of machine learning model that can be used to learn compressed representations of data. Unlike regular autoencoders, VAEs use a continuous latent space. The objective function of a VAE encourages the model to learn a latent space that captures the underlying structure of the data while also matching the prior distribution over latent variables. This makes it easier to work with and analyze the data. VAEs are particularly useful for generating new data that is similar to the input data, such as images or text.
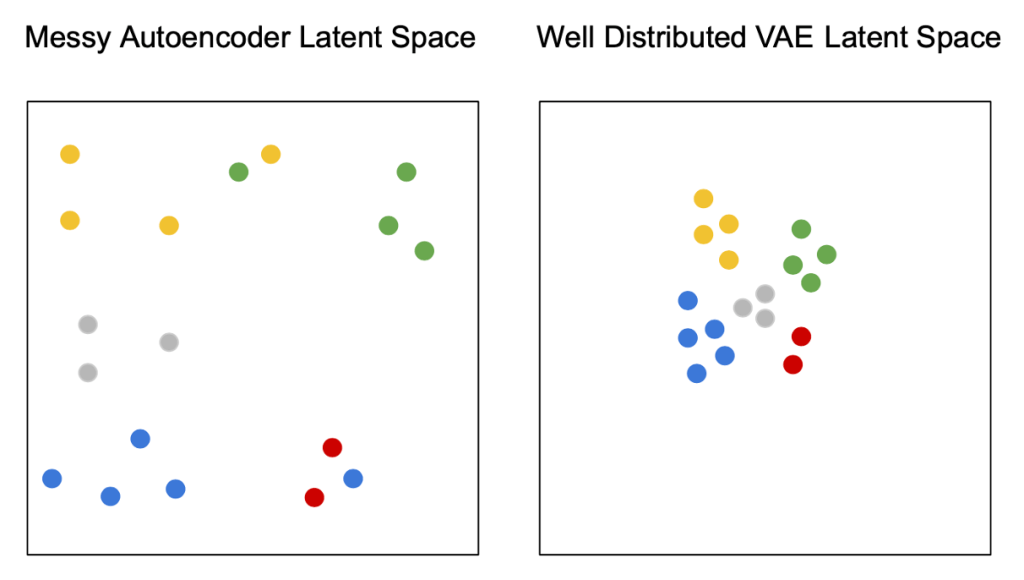
Fig. 152 Variational Autoencoders (VAE)#
Variational Autoencoders (VAE) is a type of autoencoder where the latent space is continuous.
The objective function of a VAE can be written as:
\(\mathcal{L} = \mathbb{E}_{q(z|x)}[\log p(x|z)] - D_{KL}[q(z|x) || p(z)]\)
where \(p(x)\) is the data distribution, \(q\) is the approximate posterior over latent variables and \(D_{KL}\) denotes the Kullback-Leibler divergence.
This objective function encourages the model to learn a latent space that captures the underlying structure of the data while also matching the prior distribution over latent variables.
Discrete Spaces#
Discrete spaces are a type of space that is more efficient to work with than continuous spaces. This is because a discrete space can be represented with a finite number of bits, while a continuous space requires an infinite number of bits. Discrete spaces are also easier to manipulate and reason about than continuous spaces. This is why VQ-VAE, which uses a discrete latent space, is more efficient than VAE at learning compressed representations of data. By using a finite set of discrete codes, VQ-VAE can learn compressed representations of data that are easier to work with and require less memory than VAE’s continuous representations.
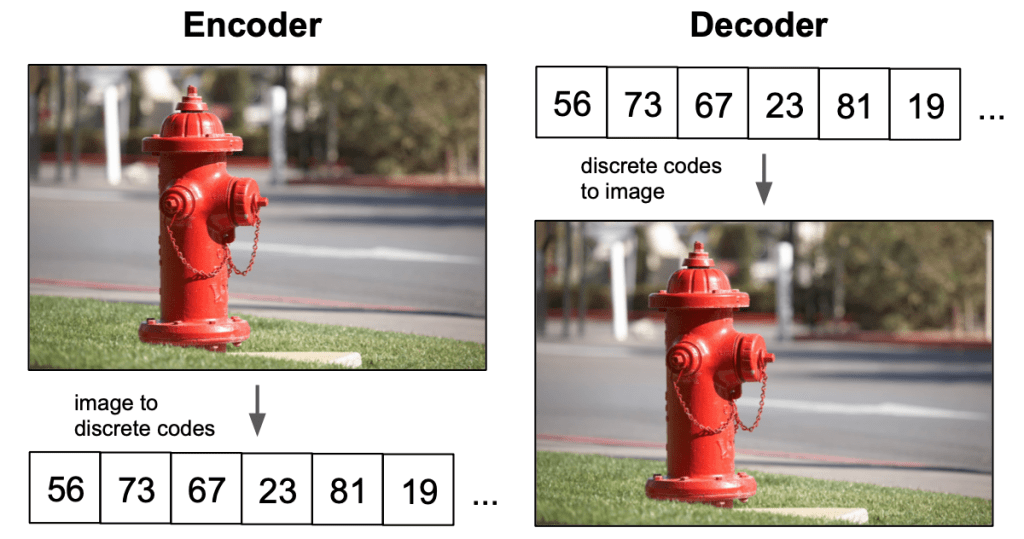
Fig. 153 Discrete Spaces#
Discrete spaces are more efficient to represent than continuous spaces.
This is because a discrete space can be represented with a finite number of bits, whereas a continuous space requires an infinite number of bits.
In addition, discrete spaces are easier to manipulate and reason about than continuous spaces.
For these reasons, VQ-VAE is more efficient than VAE at learning latent representations of data.
Uncertainty in the Posterior#
Uncertainty in the posterior arises due to soft-sampling codebook vectors from the Gumbel-Softmax distribution. This soft-sampling process creates a continuous approximation of the discrete latent space, which introduces some level of uncertainty or imprecision in the model’s predictions or estimated parameters.
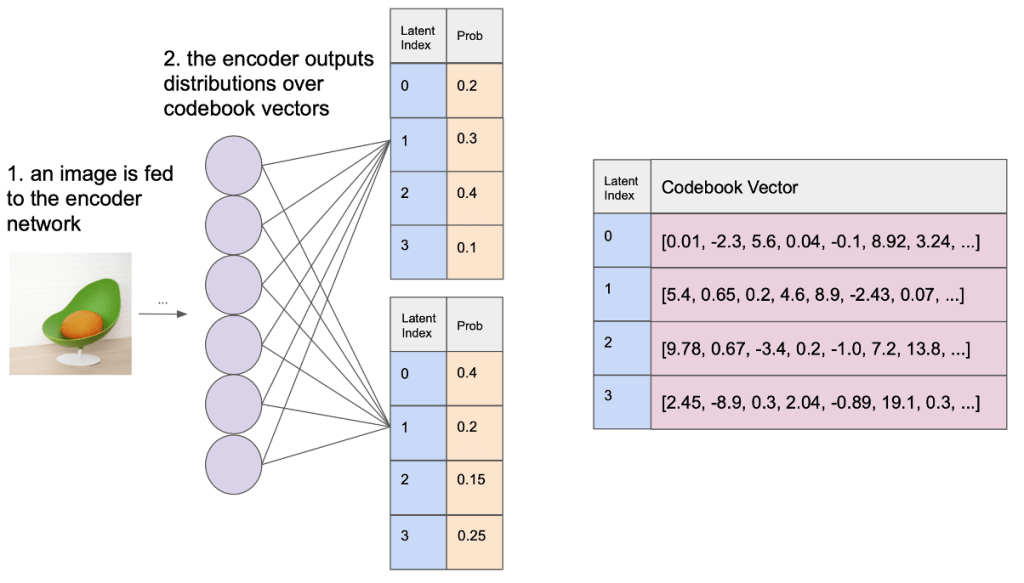
Fig. 154 Uncertainty in the Posterior#
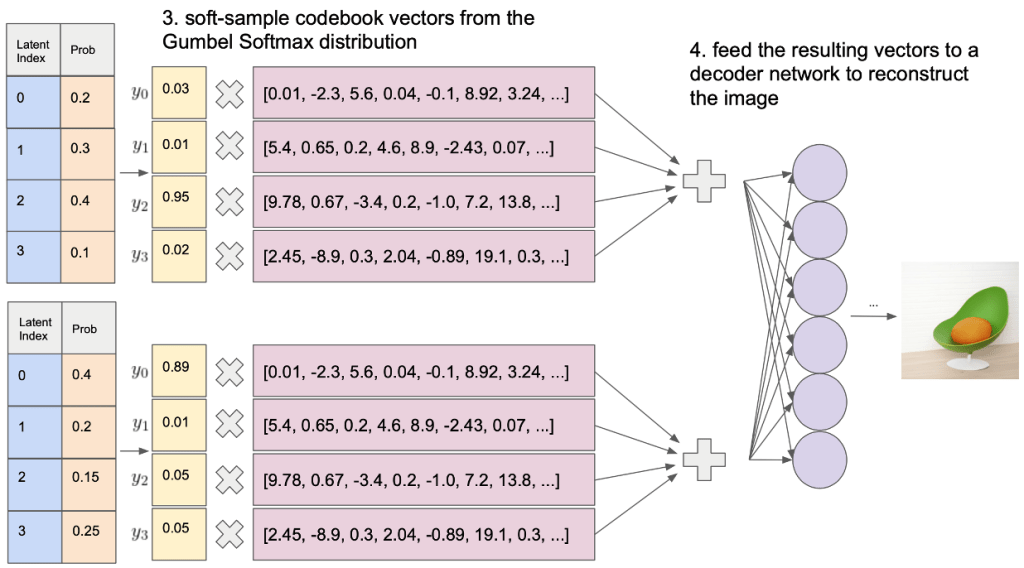
Fig. 155 Uncertainty in the Posterior#
To understand uncertainty in the posterior easily, let’s break it down into simpler terms:
Posterior: In the context of machine learning and probabilistic models, the posterior is the updated probability distribution of a model’s parameters after taking into account observed data.
Uncertainty: In this context, uncertainty refers to the lack of confidence or precision in the model’s predictions or estimated parameters.
Now, let’s talk about the Gumbel-Softmax distribution and soft-sampling codebook vectors:
Codebook vectors: In a VQ-VAE (Vector Quantized Variational AutoEncoder) model, codebook vectors are a set of fixed, learnable vectors that form a discrete latent space. The model maps its continuous latent representations to the nearest codebook vector during the training process.
Soft-sampling: Soft-sampling refers to the process of sampling codebook vectors in a “soft” manner, meaning that the samples are taken from a continuous approximation of the discrete latent space. This is done using the Gumbel-Softmax distribution.
Gumbel-Softmax distribution: The Gumbel-Softmax distribution is a technique that allows for sampling from a discrete space while maintaining gradients for backpropagation. It involves using a temperature parameter (\(\beta\)) that controls the “sharpness” of the distribution. Lower temperatures lead to a more focused distribution, while higher temperatures result in a more uniform distribution.
The Gumbel-Softmax distribution is defined as:
\(G(z;\mu,\beta) = \frac{\exp((z - \mu)/\beta)}{\sum_{k=1}^K \exp((z_k - \mu)/\beta)}\)
where \(\mu\) is the mean, \(\beta\) is the temperature and \(K\) is the number of classes.
This is useful for training models with discrete latent spaces, such as VQ-VAE.

Fig. 156 Comparison of original images (top) and reconstructions from the dVAE (bottom)#
Decoder#
DALL-E’s decoder is a GPT-3-like transformer that takes a sequence of text tokens and optional image tokens as input, understands their relationships, and generates a visual representation of the input text by producing a continuation or completion of the image.
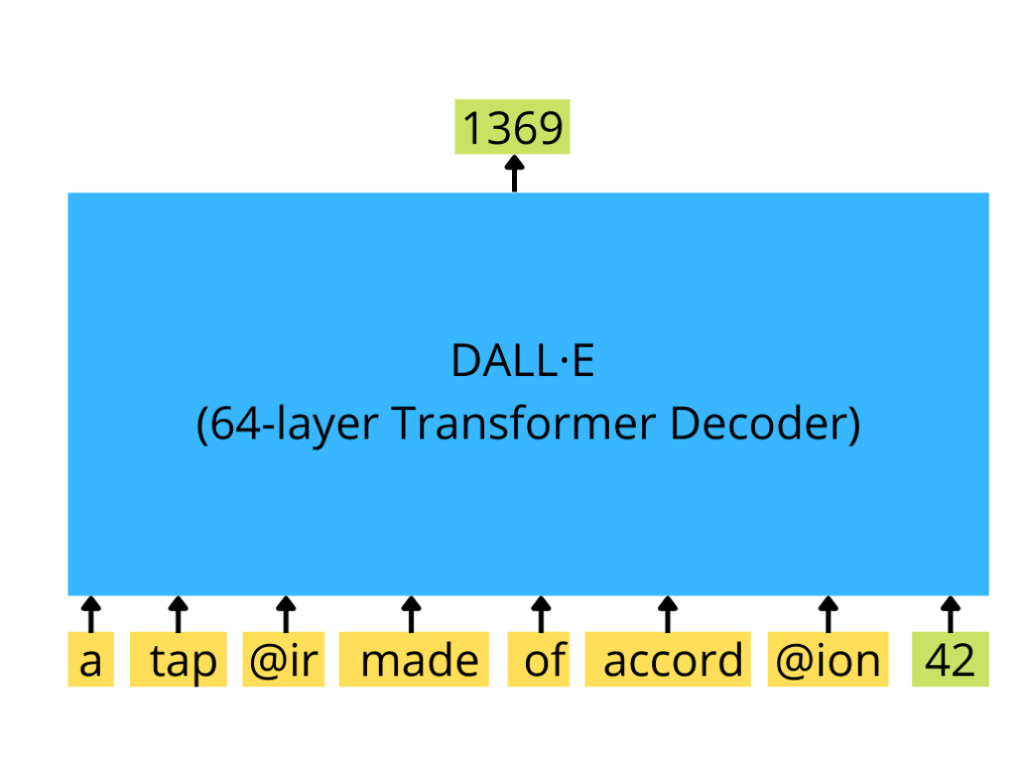
Fig. 157 Decoder#
The decoder in DALL-E is a crucial component responsible for generating images based on the input sequence of text and image tokens.
GPT-3-like transformer decoder: A transformer decoder is a neural network architecture that excels in understanding and generating sequences. In DALL-E, the decoder is similar to GPT-3, a powerful language model that has been trained on vast amounts of text.
Text tokens: These are the individual units of text (words or subwords) that the model processes. In DALL-E, text tokens are used to provide a textual description of the desired image.
Image tokens: In DALL-E, images are represented as a sequence of image tokens, which are essentially small parts of an image. These tokens are used as input to the decoder, allowing it to generate a continuation or completion of the image.
Here’s the process in simple terms:
The input sequence: A sequence of text tokens describing the desired image and, optionally, some initial image tokens are fed into the decoder.
The decoder processes the input sequence: The transformer decoder processes the input sequence, understanding the relationship between the text tokens and image tokens.
Generating image continuation: Based on the processed input sequence, the decoder generates a continuation of the image, adding new image tokens that visually represent the input text.
In the example you provided, the decoder is given a sequence with text tokens and an initial image token (with ID 42). It processes this sequence and generates a continuation of the image by producing the next image token (with ID 1369).
Sampling From a Trained DALL-E#
Sampling from a trained DALL-E involves preparing an input text description, encoding it, and feeding it to the decoder. The decoder generates a sequence of image tokens based on the input, which are then converted back into an image that represents the desired text description. The sampling process can be controlled using various strategies to influence the randomness and diversity of the generated images.
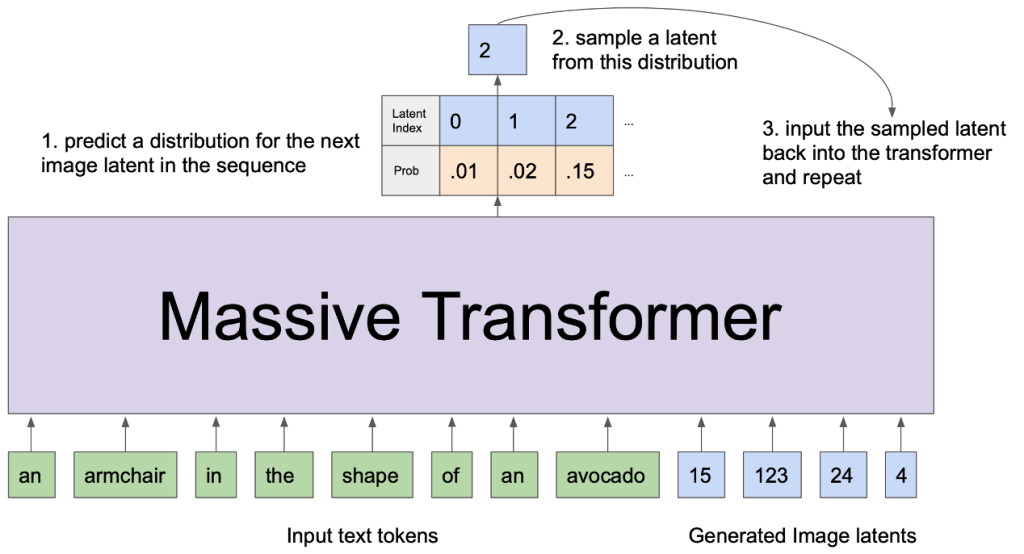
Fig. 158 Sampling From a Trained DALL-E#
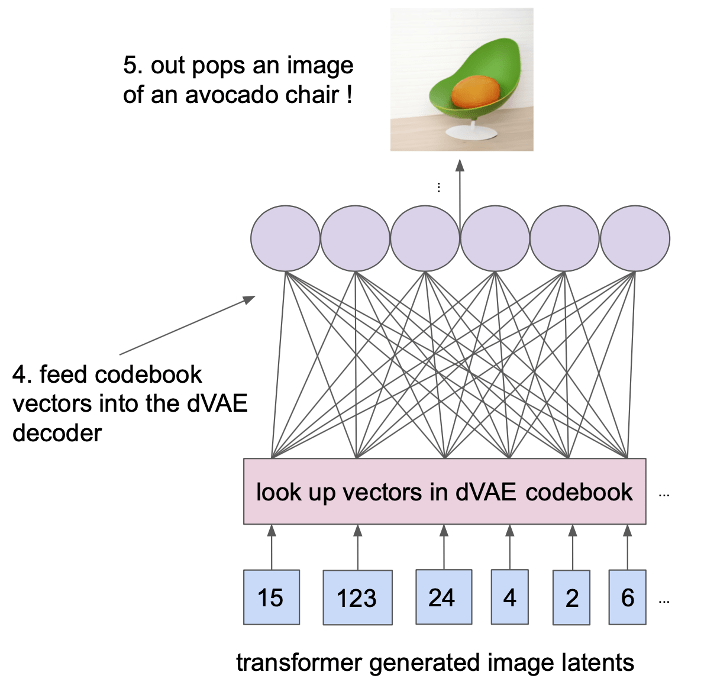
Fig. 159 Sampling From a Trained DALL-E#
Sampling from a trained DALL-E is the process of generating new images based on a textual description provided as input.
Prepare the input: Create a sequence of text tokens based on the desired textual description. This sequence will be used as input to guide the image generation process.
Encode the input: The text tokens are passed through an encoder, which converts them into a format that can be understood by the model. This typically involves mapping the text tokens to numerical representations called embeddings.
Generate image tokens: The encoded input is then fed into the DALL-E decoder. The decoder processes the input and generates a sequence of image tokens that visually represent the input text. The image tokens are generated one at a time, with each new token being conditioned on the input text tokens and previously generated image tokens.
Sampling strategy: During the image token generation process, a sampling strategy is used to control the randomness and diversity of the generated images. Common strategies include temperature-based sampling, where a higher temperature results in more diverse and random images, and top-k sampling, which restricts the token selection to the top-k most likely candidates.
Convert image tokens to an image: Once the sequence of image tokens is generated, they are converted back into an image format (e.g., a grid of pixels). This reconstructed image is the final output, which should visually represent the input text description.
DALL·E 1 Results#

Fig. 160 Several image generation examples from the original paper#
The trained model generated several samples (up to 512!) based on the text provided, then all these samples were ranked by a special model called CLIP, and the top-ranked one was chosen as the result of the model.

Fig. 161 Evaluation#
Conclusion#
The DALL-E model represents a significant breakthrough in the field of artificial intelligence, particularly in the area of image generation. By successfully combining the power of transformer-based language models with the ability to generate high-quality images from textual descriptions, DALL-E has demonstrated remarkable capabilities in the realm of creative AI applications.
This innovative model has the potential to impact a wide range of industries, such as advertising, entertainment, education, and art, by enabling the automatic generation of customized visual content based on specific user inputs. Furthermore, DALL-E serves as an inspiration for future research in the intersection of natural language processing and computer vision, potentially paving the way for more advanced AI systems that can understand and manipulate both textual and visual information.