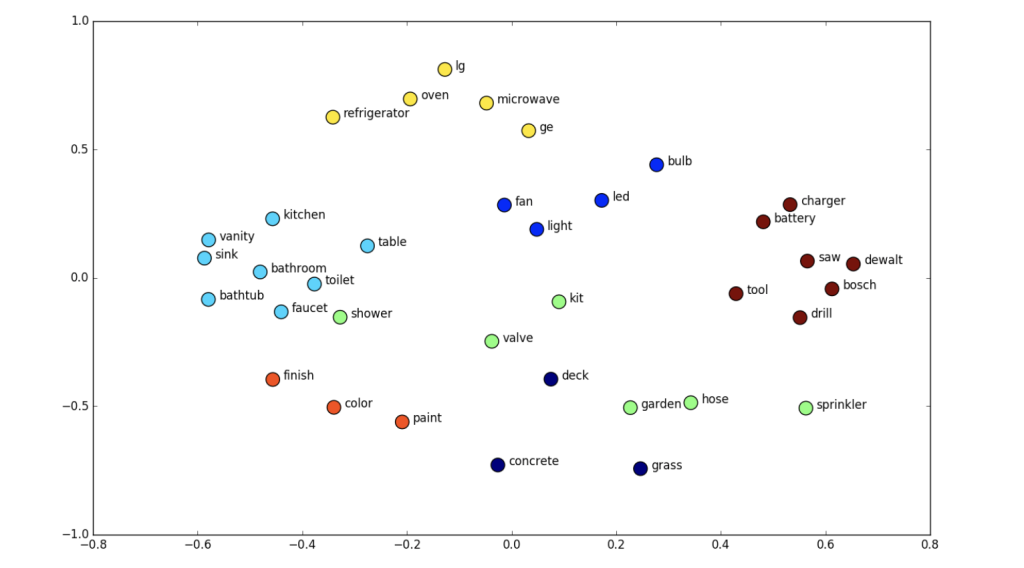
Neural Language Models#
Word embeddings were proposed by [Bengio et al., 2003] as a way to represent words as vectors.
Bengio’s method could train a neural network such that each training sentence could inform the model about a number of semantically available neighboring words, which was known as distributed representation of words. The nueural network preserved relationships between words in terms of their contexts (semantic and syntactic).
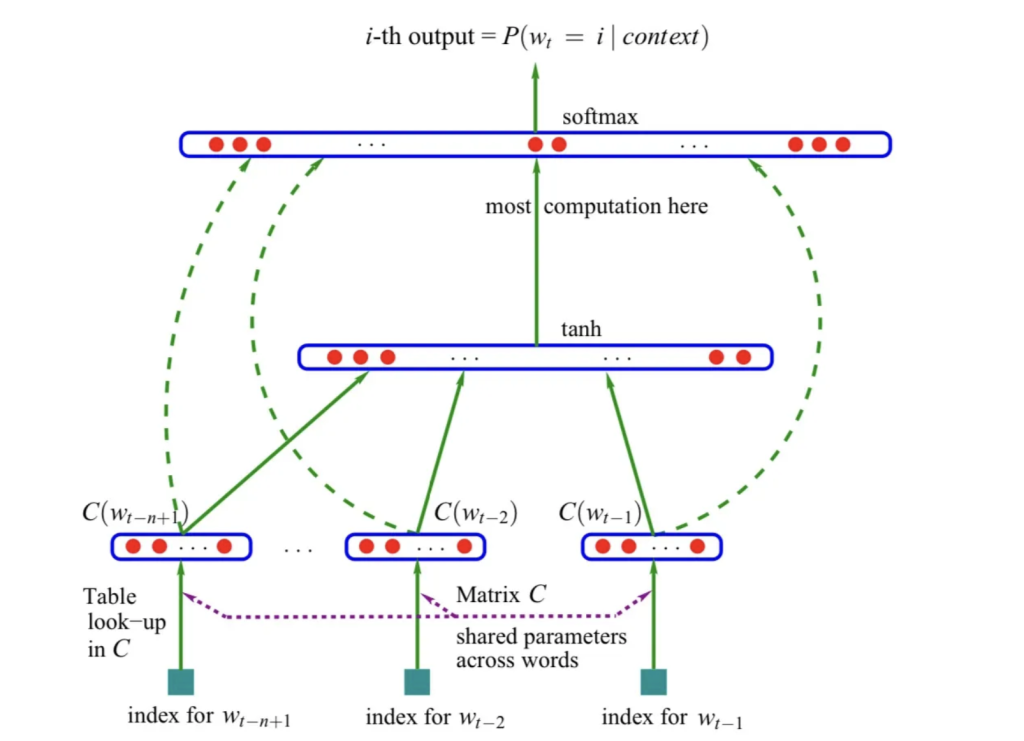
This introduced a neural network architecture approach that laid the foundation for many current approaches.
This neural network has three components:
Embedding layer: maps words to vectors, the parameters are shared across the network.
Hidden layer: a fully connected layer with a non-linear activation function.
Output layer: produces a probability distribution over the vocabulary using a softmax function.
sentences = ["i like apples", "i like bananas", "i hate oranges"]
Step 1: Indexing the words.#
For each word in the sentence, we assign an index.
words = " ".join(sentences).split()
word_list = list(set(words))
word_to_id = {w: i for i, w in enumerate(word_list)}
id_to_word = {i: w for w, i in word_to_id.items()}
vocab_size = len(word_to_id)
print("vocab_size:", vocab_size)
vocab_size: 6
Step 2: Building the model.#
An embedding layer is a lookup table that maps each word to a vector.
Once the input index of the word is embedded, it is passed through the first hidden layer with bias added to it.
The output of the first hidden layer is passed through a tanh activation function.
The output from the embedding layer is also passed through the final layer where the output of the tanh layer is added to it.
import torch
import torch.nn as nn
import torch.optim as optim
class NNLM(nn.Module):
def __init__(self, vocab_size, embedding_size, num_hiddens, num_steps):
self.num_steps = num_steps
self.embedding_size = embedding_size
super(NNLM, self).__init__()
self.embeddings = nn.Embedding(
vocab_size, embedding_size
) # embedding layer or look up table
self.hidden1 = nn.Linear(num_steps * embedding_size, num_hiddens, bias=False)
self.ones = nn.Parameter(torch.ones(num_hiddens))
self.hidden2 = nn.Linear(num_hiddens, vocab_size, bias=False)
self.hidden3 = nn.Linear(
num_steps * embedding_size, vocab_size, bias=False
) # final layer
self.bias = nn.Parameter(torch.ones(vocab_size))
def forward(self, X):
word_embeds = self.embeddings(X) # embeddings
X = word_embeds.view(-1, self.num_steps * self.embedding_size) # first layer
tanh = torch.tanh(self.ones + self.hidden1(X)) # tanh layer
output = (
self.bias + self.hidden3(X) + self.hidden2(tanh)
) # summing up all the layers with bias
return word_embeds, output
Step 3: Loss and optimization function.#
Now that we have the model, we need to define the loss function and the optimization function.
We are using the cross-entropy loss function and the Adam optimizer.
The cross-entropy loss function is made up of two parts:
The softmax function: this is used to normalize the output of the model so that the sum of the probabilities of all the words in the vocabulary is equal to one.
The negative log-likelihood: this is used to calculate the loss.
num_steps = 2
num_hiddens = 2
embedding_size = 2
model = NNLM(vocab_size, embedding_size, num_hiddens, num_steps)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
Step 4: Training the model.#
Finally, we train the model.
def make_batch(sentences, word_to_id):
input_batch = []
target_batch = []
for sent in sentences:
word = sent.split()
input = [word_to_id[n] for n in word[:-1]]
target = word_to_id[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
input_batch, target_batch = make_batch(sentences, word_to_id)
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
for epoch in range(5000):
optimizer.zero_grad()
embeddings, output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print("Epoch:", "%04d" % (epoch + 1), "cost =", "{:.6f}".format(loss))
loss.backward()
optimizer.step()
Epoch: 1000 cost = 0.488254
Epoch: 2000 cost = 0.466801
Epoch: 3000 cost = 0.463683
Epoch: 4000 cost = 0.462811
Epoch: 5000 cost = 0.462459
# Test
predict = model(input_batch)[1].data.max(1, keepdim=True)[1]
print(
[sen.split()[:2] for sen in sentences],
"->",
[id_to_word[n.item()] for n in predict.squeeze()],
)
[['i', 'like'], ['i', 'like'], ['i', 'hate']] -> ['bananas', 'bananas', 'oranges']
Summary#
Word embeddings are a way to represent words as low-dimensional dense vectors.
These embeddings have associated learnable vectors, which optimize themselves through back propagation.
Essentially, the embedding layer is the first layer of a neural network.
They try to preserve the semantic and syntactic relationships between words.