Putting them together in a pipeline#
from ekorpkit import eKonf
if eKonf.is_colab():
eKonf.mount_google_drive()
ws = eKonf.set_workspace(
workspace="/workspace",
project="ekorpkit-book/exmaples",
task="esg",
log_level="INFO"
)
print("version:", ws.version)
print("project_dir:", ws.project_dir)
version: 0.1.40.post0.dev67
project_dir: /workspace/projects/ekorpkit-book/exmaples
time: 518 ms (started: 2023-01-05 05:20:52 +00:00)
Preparing additional polarity data#
from ekorpkit.datasets.dataset import Dataset
cfg = eKonf.compose("dataset=dataset")
cfg.name = 'esg_polarity_kr'
cfg.data_dir = cfg.path.data_dir
ds_pol = Dataset(**cfg)
data_files = ds_pol.data_files
data_files
INFO:ekorpkit.datasets.config:Loaded info file: /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_polarity_kr/info-esg_polarity_kr.yaml
INFO:ekorpkit.info.column:index: index, index of data: index, columns: ['id', 'text', 'labels', 'split'], id: ['id']
INFO:ekorpkit.info.column:Adding id [split] to ['id']
INFO:ekorpkit.info.column:Added id [split], now ['id', 'split']
INFO:ekorpkit.info.column:Added a column [split] with value [train]
INFO:ekorpkit.info.column:Added a column [split] with value [test]
INFO:ekorpkit.info.column:Added a column [split] with value [dev]
{'train': 'esg_polarity_kr-train.parquet',
'test': 'esg_polarity_kr-test.parquet',
'dev': 'esg_polarity_kr-dev.parquet'}
time: 1.51 s (started: 2023-01-05 05:21:19 +00:00)
pol_file = ws.project_dir / "esg/outputs/esg_polarity_labels/esg_polarity_labels(0)_export.parquet"
eKonf.copy(pol_file, ds_pol.data_dir)
pol_data = eKonf.load_data(pol_file)
# summary of labels column
pol_data["labels"].value_counts()
INFO:ekorpkit.ekonf:copied /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_labels/esg_polarity_labels(0)_export.parquet to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_polarity_kr
Neutral 622
Positive 437
Negative 99
Name: labels, dtype: int64
time: 27.9 ms (started: 2023-01-05 05:21:23 +00:00)
Training further on the additional polarity data#
from ekorpkit.models.transformer.simple import SimpleClassification
trained_model = "esg/models/esg_polarity-classification"
cfg = eKonf.compose('task=simple.classification')
cfg.name = "esg_polarity_further_train"
cfg.dataset.data_dir = ds_pol.data_dir
cfg.dataset.data_files = pol_file
cfg.dataset.test_size = 0.2
cfg.dataset.shuffle = True
cfg.dataset.seed = 1329829118
cfg.model.model_name_or_path = f"{ws.project_dir}/{trained_model}"
# cfg.model.model_name_or_path = "entelecheia/ekonelectra-base-discriminator"
cfg.trainer.num_train_epochs = 10
cfg.trainer.max_seq_length = 256
cfg.trainer.train_batch_size = 128
cfg.trainer.eval_batch_size = 128
sm = SimpleClassification(**cfg)
Show code cell output
2023-01-05 05:21:24.990185: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-01-05 05:21:25.574969: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-01-05 05:21:25.575033: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-01-05 05:21:25.575039: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
time: 3.56 s (started: 2023-01-05 05:21:24 +00:00)
sm.train()
sm.eval()
Show code cell output
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and test with ratio 0.2
INFO:ekorpkit.datasets.config:Shuffling the dataframe with seed 1329829118
INFO:ekorpkit.datasets.config:Train data: (926, 6)
INFO:ekorpkit.datasets.config:Test data: (232, 6)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_3_2
INFO:simpletransformers.classification.classification_model: Starting fine-tuning.
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_polarity_further_train-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.6944896761916455, 'acc': 0.8232758620689655, 'eval_loss': 0.47384417057037354}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_further_train/configs/esg_polarity_further_train(23)_config.yaml
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_polarity_further_train-classification/best_model
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 2.34112692 -0.67927313 -1.39262569]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_further_train/esg_polarity_further_train(23)_preds.parquet
INFO:numexpr.utils:Note: NumExpr detected 32 cores but "NUMEXPR_MAX_THREADS" not set, so enforcing safe limit of 8.
INFO:numexpr.utils:NumExpr defaulting to 8 threads.
Accuracy: 0.8448275862068966
Precison: 0.8644108938029865
Recall: 0.8448275862068966
F1 Score: 0.8501989907520767
Model Report:
___________________________________________________
precision recall f1-score support
Negative 0.54 0.83 0.65 18
Neutral 0.84 0.86 0.85 113
Positive 0.95 0.83 0.89 101
accuracy 0.84 232
macro avg 0.78 0.84 0.80 232
weighted avg 0.86 0.84 0.85 232
INFO:ekorpkit.visualize.base:Saved figure to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_further_train/esg_polarity_further_train(23)_confusion_matrix.png
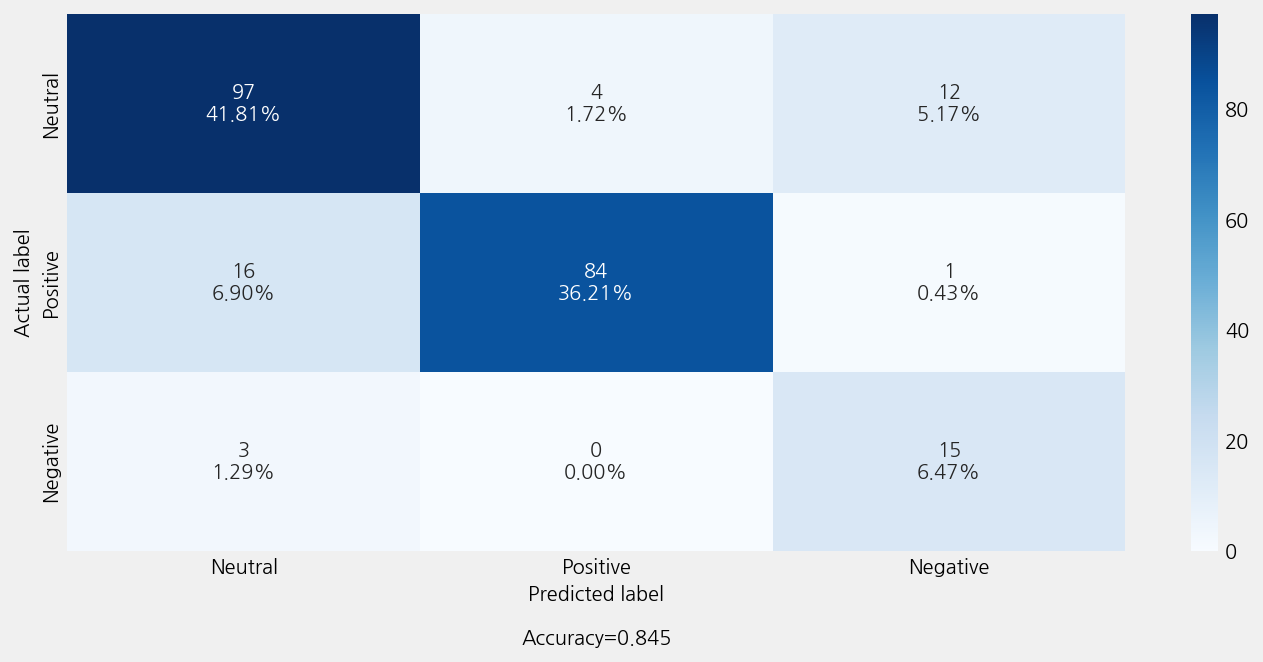
time: 1min 21s (started: 2023-01-05 05:21:28 +00:00)
pol_preds = sm.predict(ds_pol.data)
print(pol_preds.shape)
cols = ["text", "labels", "pred_labels", "pred_probs"]
pol_preds[cols].head()
INFO:ekorpkit.io.file:Concatenating 3 dataframes
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 0.91504776 -1.6142416 0.5779075 ]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_further_train/esg_polarity_further_train(23)_preds.parquet
(13616, 7)
| text | labels | pred_labels | pred_probs | |
|---|---|---|---|---|
| 0 | 헌법재판소는 먼저 고발권 행사의 재량성에 대해서는 공정거래법은 제71조에서 '...... | Negative | Neutral | 0.557561 |
| 1 | 특히, 그룹내 업종도 다르고 재무구조도 다른 계열사들이 그룹으로 묶여지는 특수한 지... | Neutral | Neutral | 0.928241 |
| 2 | 2018년 신규 취업자수는 36만명 증가하고, 전체 취업자 증가율은 1.4%로 20... | Neutral | Neutral | 0.925548 |
| 3 | 앞서 분석한 대로 5월엔 펀더멘털 개선과 위험 요인들이 h지수의 방향을 좌우할 것이... | Neutral | Neutral | 0.896465 |
| 4 | 재생에너지의 성장 속도는 향후 10년 안에 세계 주요 지역의 전통 에너지원 (con... | Positive | Positive | 0.942301 |
time: 31.6 s (started: 2023-01-05 05:22:49 +00:00)
records_with_label_error = sm.find_label_errors(pol_preds)
print(len(records_with_label_error))
records_with_label_error[0]
INFO:ekorpkit.models.transformer.simple:Created 13616 records
3126
TextClassificationRecord(text='재생에너지는 태양 열, 태양광, 풍력, 수력(2003년 이후 10mw 이상의 대규모 수력발전 포함, 펌프 저장 수력 은 제외), 조력, 지열, 바이오, 폐기물로 구성되며, 바이오는 바이오가스, lfg(landfill gas), 바이오디젤, 우드 칩 & 펠렛, 성형탄, 임산연료, 폐목재, 흑액, 하수슬러지 고형연 료, 바이오 srf(solid refuse fuel), 바이오 중유로 구성되고, 폐기물은 폐가스, 산업폐기물, 생활폐기물, 대형 도시 쓰레기, 시멘트 킬린 보조 연료, rdf(refuse-derived fuel), rpf(refuse plastic fuel), tdf(tire-derived fuel), srf, 정제 연료유, 폐목재로 구성되며, 신에너지는 연료전지와 igcc(integrated gasification combined cycle)을 포함한 다(에너지경제연구원, 2017)', inputs={'text': '재생에너지는 태양 열, 태양광, 풍력, 수력(2003년 이후 10mw 이상의 대규모 수력발전 포함, 펌프 저장 수력 은 제외), 조력, 지열, 바이오, 폐기물로 구성되며, 바이오는 바이오가스, lfg(landfill gas), 바이오디젤, 우드 칩 & 펠렛, 성형탄, 임산연료, 폐목재, 흑액, 하수슬러지 고형연 료, 바이오 srf(solid refuse fuel), 바이오 중유로 구성되고, 폐기물은 폐가스, 산업폐기물, 생활폐기물, 대형 도시 쓰레기, 시멘트 킬린 보조 연료, rdf(refuse-derived fuel), rpf(refuse plastic fuel), tdf(tire-derived fuel), srf, 정제 연료유, 폐목재로 구성되며, 신에너지는 연료전지와 igcc(integrated gasification combined cycle)을 포함한 다(에너지경제연구원, 2017)'}, prediction=[('Neutral', 0.029363089614303225), ('Positive', 0.9645883781616761), ('Negative', 0.006048532224020738)], prediction_agent=None, annotation='Neutral', annotation_agent=None, multi_label=False, explanation=None, id=None, metadata={'id': 20632, 'split': 'train', 'label_error_candidate': 0}, status='Validated', event_timestamp=None, metrics=None, search_keywords=None)
time: 5.31 s (started: 2023-01-05 05:23:21 +00:00)
# remove rows from preds that have label errors
pol_preds_new = pol_preds.copy()
for record in records_with_label_error:
metadata = record.metadata
pol_preds_new = pol_preds_new[pol_preds_new.id != metadata["id"]]
print(len(pol_preds_new))
filename = "esg_polarity_data_validated.parquet"
eKonf.save_data(pol_preds_new, filename, ds_pol.data_dir)
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_polarity_kr/esg_polarity_data_validated.parquet
10490
time: 3.41 s (started: 2023-01-05 05:23:26 +00:00)
data_pol_merged = eKonf.concat_data([pol_preds_new[['text', 'labels']], pol_data[['text', 'labels']]], axis=0)
print(data_pol_merged.shape)
print(data_pol_merged.labels.value_counts())
# Save data
valid_pol_file = "esg_polarity_labels_validated.parquet"
valid_data_dir = ws.project_dir / "esg/data/esg_polarity_validated"
eKonf.save_data(data_pol_merged, valid_pol_file, valid_data_dir)
INFO:ekorpkit.io.file:Concatenating 2 dataframes
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_polarity_validated/esg_polarity_labels_validated.parquet
(11648, 2)
Neutral 8743
Positive 2137
Negative 768
Name: labels, dtype: int64
time: 544 ms (started: 2023-01-05 05:23:30 +00:00)
from ekorpkit.models.transformer.simple import SimpleClassification
trained_model = "esg/models/esg_polarity-classification"
valid_pol_file = "esg_polarity_labels_validated.parquet"
valid_data_dir = ws.project_dir / "esg/data/esg_polarity_validated"
cfg = eKonf.compose('task=simple.classification')
cfg.name = "esg_polarity_validated"
cfg.dataset.data_dir = valid_data_dir
cfg.dataset.data_files = valid_pol_file
cfg.dataset.test_size = 0.2
cfg.dataset.dev_size = 0.2
cfg.dataset.shuffle = True
cfg.dataset.seed = 1329829118
cfg.model.model_name_or_path = f"{ws.project_dir}/{trained_model}"
cfg.trainer.num_train_epochs = 10
cfg.trainer.max_seq_length = 256
cfg.trainer.train_batch_size = 128
cfg.trainer.eval_batch_size = 128
sm = SimpleClassification(**cfg)
time: 1.8 s (started: 2023-01-05 05:23:30 +00:00)
sm.train()
sm.eval()
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and test with ratio 0.2
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and dev with ratio 0.2
INFO:ekorpkit.datasets.config:Shuffling the dataframe with seed 1329829118
INFO:ekorpkit.datasets.config:Train data: (7454, 2)
INFO:ekorpkit.datasets.config:Test data: (2330, 2)
INFO:ekorpkit.datasets.config:Dev data: (1864, 2)
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_3_2
INFO:simpletransformers.classification.classification_model: Starting fine-tuning.
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8370756314020869, 'acc': 0.9361587982832618, 'eval_loss': 0.1948709785938263}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8351891378637732, 'acc': 0.9281115879828327, 'eval_loss': 0.18297020494937896}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8416612963899948, 'acc': 0.9329399141630901, 'eval_loss': 0.19620483368635178}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8106017713175628, 'acc': 0.9136266094420601, 'eval_loss': 0.2883289317289988}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8517777272479437, 'acc': 0.9393776824034334, 'eval_loss': 0.21728213826815287}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8428568844583993, 'acc': 0.9361587982832618, 'eval_loss': 0.2663285652796427}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8046839102325267, 'acc': 0.9114806866952789, 'eval_loss': 0.36101144552230835}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8316201654065506, 'acc': 0.930793991416309, 'eval_loss': 0.30500775774319966}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.845083717375899, 'acc': 0.9366952789699571, 'eval_loss': 0.285999862353007}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8351849488988791, 'acc': 0.9313304721030042, 'eval_loss': 0.2960137814283371}
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_polarity_validated-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_3_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8420461010091653, 'acc': 0.934763948497854, 'eval_loss': 0.25463688023094283}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_validated/configs/esg_polarity_validated(5)_config.yaml
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_polarity_validated-classification/best_model
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 4.14652348 -1.96653938 -1.80128765]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_validated/esg_polarity_validated(5)_preds.parquet
Accuracy: 0.9343347639484979
Precison: 0.9403512413688508
Recall: 0.9343347639484979
F1 Score: 0.935814490942164
Model Report:
___________________________________________________
precision recall f1-score support
Negative 0.80 0.92 0.86 145
Neutral 0.98 0.93 0.96 1746
Positive 0.83 0.95 0.88 439
accuracy 0.93 2330
macro avg 0.87 0.93 0.90 2330
weighted avg 0.94 0.93 0.94 2330
INFO:ekorpkit.visualize.base:Saved figure to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_validated/esg_polarity_validated(5)_confusion_matrix.png
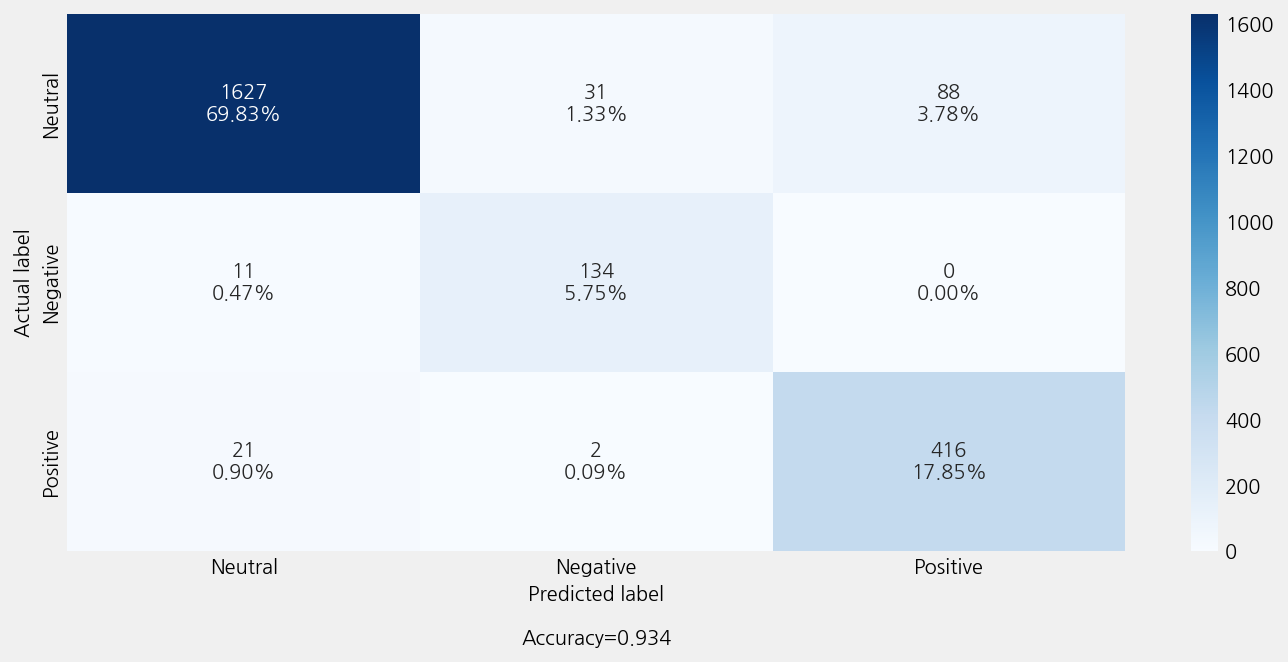
time: 8min 19s (started: 2023-01-05 05:23:32 +00:00)
Preparing invalid topic data#
from ekorpkit.datasets.dataset import Dataset
cfg = eKonf.compose("dataset=dataset")
cfg.name = "esg_invalid_kr"
cfg.data_dir = cfg.path.data_dir
ds_inval = Dataset(**cfg)
print(ds_inval.data["labels"].value_counts())
INFO:ekorpkit.datasets.config:Loaded info file: /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_invalid_kr/info-esg_invalid_kr.yaml
INFO:ekorpkit.info.column:index: index, index of data: None, columns: ['text', 'labels', 'annotation'], id: ['id']
INFO:ekorpkit.info.column:Adding id [split] to ['id']
INFO:ekorpkit.info.column:Added id [split], now ['id', 'split']
INFO:ekorpkit.info.column:Added a column [split] with value [train]
INFO:ekorpkit.info.column:Added a column [split] with value [dev]
INFO:ekorpkit.info.column:Added a column [split] with value [test]
INFO:ekorpkit.io.file:Concatenating 3 dataframes
Validated 198
Discarded 173
Name: labels, dtype: int64
time: 960 ms (started: 2023-01-05 05:31:52 +00:00)
file = ws.project_dir / "esg/outputs/esg_topic_labels/esg_topic_labels(0)_export.parquet"
tp_add = eKonf.load_data(file)
# summary of labels column
print(tp_add["labels"].value_counts())
# change value of labels column
# UNKNOWN -> Discarded
# Other values -> Validated
tp_add["labels"] = tp_add["labels"].apply(lambda x: "Discarded" if x == "UNKNOWN" else "Validated")
print(tp_add["labels"].value_counts())
UNKNOWN 212
E-환경혁신 72
G-지배구조 66
G-기업윤리/불공정/소송 57
E-기후변화 53
S-기업(공급망)동반성장/상생 33
ESG 24
S-고용 20
S-소비자 14
S-사회공헌 11
S-재해/안전관리 9
E-환경영향 5
Name: labels, dtype: int64
Validated 364
Discarded 212
Name: labels, dtype: int64
time: 16.8 ms (started: 2023-01-05 05:31:53 +00:00)
# combine two datasets
data_inval = eKonf.concat_data([ds_inval.data, tp_add], axis=0)
print(data_inval.labels.value_counts())
data_inval.head()
# Save data
file_inval = "esg_invalid_kr_merged.parquet"
eKonf.save_data(data_inval, file_inval, ds_inval.data_dir)
INFO:ekorpkit.io.file:Concatenating 3 dataframes
INFO:ekorpkit.io.file:Concatenating 2 dataframes
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_invalid_kr/esg_invalid_kr_merged.parquet
Validated 562
Discarded 385
Name: labels, dtype: int64
time: 101 ms (started: 2023-01-05 05:31:53 +00:00)
Training an invalid topic classifier#
from ekorpkit.models.transformer.simple import SimpleClassification
cfg = eKonf.compose('task=simple.classification')
cfg.name = "esg_topic_invalid_merged"
cfg.dataset.data_dir = ds_inval.data_dir
cfg.dataset.data_files = file_inval
cfg.dataset.test_size = 0.2
# cfg.dataset.dev_size = 0.2
cfg.dataset.seed = 3247616750
cfg.dataset.shuffle = True
cfg.model.model_name_or_path = "entelecheia/ekonelectra-base-discriminator"
cfg.trainer.num_train_epochs = 10
cfg.trainer.max_seq_length = 256
cfg.trainer.train_batch_size = 128
cfg.trainer.eval_batch_size = 128
sm_inval = SimpleClassification(**cfg)
time: 3.59 s (started: 2023-01-05 05:31:53 +00:00)
cv_preds_inval = sm_inval.cross_val_predict(cv=3, dev_size=0)
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and test with ratio 0.2
INFO:ekorpkit.datasets.config:Shuffling the dataframe with seed 3247616750
INFO:ekorpkit.datasets.config:Train data: (757, 8)
INFO:ekorpkit.datasets.config:Test data: (190, 8)
INFO:ekorpkit.io.file:Concatenating 2 dataframes
INFO:ekorpkit.datasets.config:Train data: (631, 8)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_merged-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.4691283585240593, 'tp': 75, 'tn': 163, 'fp': 31, 'fn': 47, 'auroc': 0.7881527801250634, 'auprc': 0.6895470358751884, 'acc': 0.7531645569620253, 'eval_loss': 0.5734125177065531}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/configs/esg_topic_invalid_merged(18)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 0
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_merged-classification/best_model
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 0.01894244 -0.1884751 ]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/esg_topic_invalid_merged(18)_preds.parquet
INFO:ekorpkit.datasets.config:Train data: (631, 11)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_merged-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.4636900547983257, 'tp': 159, 'tn': 77, 'fp': 50, 'fn': 30, 'auroc': 0.795838020247469, 'auprc': 0.8471301983903201, 'acc': 0.7468354430379747, 'eval_loss': 0.5375698208808899}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/configs/esg_topic_invalid_merged(19)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 1
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 0.28047922 -0.40265536]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/esg_topic_invalid_merged(19)_preds.parquet
INFO:ekorpkit.datasets.config:Train data: (632, 11)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_merged-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.4950372223947054, 'tp': 134, 'tn': 102, 'fp': 34, 'fn': 45, 'auroc': 0.8179838974696024, 'auprc': 0.8595886193597174, 'acc': 0.7492063492063492, 'eval_loss': 0.5066773494084676}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/configs/esg_topic_invalid_merged(20)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 2
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [-0.09800404 -0.02036337]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/esg_topic_invalid_merged(20)_preds.parquet
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_merged/esg_topic_invalid_merged(20)_cv.parquet
time: 3min 56s (started: 2023-01-05 05:31:57 +00:00)
cols = ["text", "labels", "pred_labels", "raw_preds", "pred_probs"]
cv_preds_inval = cv_preds_inval[cols].reset_index()
time: 4.57 ms (started: 2023-01-05 05:35:54 +00:00)
inval_cv_filename = "esg_invalid_cv_preds.parquet"
eKonf.save_data(cv_preds_inval, inval_cv_filename, ds_inval.data_dir)
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_invalid_kr/esg_invalid_cv_preds.parquet
time: 89.7 ms (started: 2023-01-05 05:35:54 +00:00)
inval_cv_filename = "esg_invalid_cv_preds.parquet"
cv_preds_inval = eKonf.load_data(inval_cv_filename, ds_inval.data_dir)
time: 17.8 ms (started: 2023-01-05 05:35:54 +00:00)
records_with_label_error = sm_inval.find_label_errors(cv_preds_inval, meta_columns=["index"])
print(len(records_with_label_error))
print(records_with_label_error[0])
# remove rows from preds that have label errors
data_inval_cved = cv_preds_inval.copy()
for record in records_with_label_error:
metadata = record.metadata
data_inval_cved = data_inval_cved[data_inval_cved.index != metadata["index"]]
print(len(data_inval_cved))
inval_cved_filename = "esg_invalid_data_cved.parquet"
eKonf.save_data(data_inval_cved, inval_cved_filename, ds_inval.data_dir)
INFO:ekorpkit.models.transformer.simple:Created 947 records
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_invalid_kr/esg_invalid_data_cved.parquet
113
text=' LG화학이 서울대와 손잡고 인공지능(AI)과 빅데이터를 통한 디지털 전환(DX·Digital Transformation)에 속도를 낸다 29일 LG화학은 서울대 공과대학에서 서울대와 \'LG화학-서울대 DX 산학협력센터\' 설립 협약식을 개최했다고 밝혔다 LG화학과 서울대는 DX 분야 산학협력을 통해 다양한 과제를 발굴해 수행하고 디지털 혁신을 선도할 인재를 양성하기 위해 협력해나간다는 계획이다 양측은 △DX 산학협력 과제 추진 △DX 핵심 인력 양성 교육 실시 △산학장학생 제도 운영 등 3개 분야에서 협력을 약속했다 DX 산학협력센터는 다음달부터 서울대 공과대학에서 운영된다 양측은 먼저 생산·품질·연구개발(R&D)·마케팅 등 주요 핵심 영역에서 딥러닝, 데이터 마이닝 등 디지털 기술을 적용할 수 있는 공동 핵심과제를 발굴하고 수행할 계획이다 이를 위해 다음 달까지 후보 과제를 발굴·선정해 약 1년에 걸쳐 수행하고 후속 과제도 발굴할 예정이다 LG화학 임직원들을 대상으로 DX 핵심 인력 양성 교육을 진행하고 서울대 석·박사 산학장학생 제도를 운영하는 등 디지털 분야 미래 인재 육성과 산업 경쟁력 강화에도 노력할 방침이다 김성민 LG화학 CHO는 "AI, 빅데이터 등 4차 산업혁명과 디지털 전환이라는 세계적인 흐름에 발맞추기 위해 핵심 기술 및 관련 제품을 스스로 개발할 수 있는 인재를 육성하는 등 DX 역량을 강화하겠다"고 말했다 LG화학은 올해 DX 전담조직을 신설하고 IT 시스템의 90% 이상 클라우드 전환, 업무 지원 로봇 및 소프트웨어 표준 도입 등을 수행하는 등 디지털 전환에 집중하고 있다 [최근도 기자] ' inputs={'text': ' LG화학이 서울대와 손잡고 인공지능(AI)과 빅데이터를 통한 디지털 전환(DX·Digital Transformation)에 속도를 낸다 29일 LG화학은 서울대 공과대학에서 서울대와 \'LG화학-서울대 DX 산학협력센터\' 설립 협약식을 개최했다고 밝혔다 LG화학과 서울대는 DX 분야 산학협력을 통해 다양한 과제를 발굴해 수행하고 디지털 혁신을 선도할 인재를 양성하기 위해 협력해나간다는 계획이다 양측은 △DX 산학협력 과제 추진 △DX 핵심 인력 양성 교육 실시 △산학장학생 제도 운영 등 3개 분야에서 협력을 약속했다 DX 산학협력센터는 다음달부터 서울대 공과대학에서 운영된다 양측은 먼저 생산·품질·연구개발(R&D)·마케팅 등 주요 핵심 영역에서 딥러닝, 데이터 마이닝 등 디지털 기술을 적용할 수 있는 공동 핵심과제를 발굴하고 수행할 계획이다 이를 위해 다음 달까지 후보 과제를 발굴·선정해 약 1년에 걸쳐 수행하고 후속 과제도 발굴할 예정이다 LG화학 임직원들을 대상으로 DX 핵심 인력 양성 교육을 진행하고 서울대 석·박사 산학장학생 제도를 운영하는 등 디지털 분야 미래 인재 육성과 산업 경쟁력 강화에도 노력할 방침이다 김성민 LG화학 CHO는 "AI, 빅데이터 등 4차 산업혁명과 디지털 전환이라는 세계적인 흐름에 발맞추기 위해 핵심 기술 및 관련 제품을 스스로 개발할 수 있는 인재를 육성하는 등 DX 역량을 강화하겠다"고 말했다 LG화학은 올해 DX 전담조직을 신설하고 IT 시스템의 90% 이상 클라우드 전환, 업무 지원 로봇 및 소프트웨어 표준 도입 등을 수행하는 등 디지털 전환에 집중하고 있다 [최근도 기자] '} prediction=[('Discarded', 0.2646642609779317), ('Validated', 0.7353357390220683)] prediction_agent=None annotation='Discarded' annotation_agent=None multi_label=False explanation=None id=None metadata={'index': 276, 'label_error_candidate': 0} status='Validated' event_timestamp=None metrics=None search_keywords=None
834
time: 488 ms (started: 2023-01-05 05:35:54 +00:00)
from ekorpkit.models.transformer.simple import SimpleClassification
inval_cved_filename = "esg_invalid_data_cved.parquet"
cfg = eKonf.compose('task=simple.classification')
cfg.name = "esg_topic_invalid_cved"
cfg.dataset.data_dir = ds_inval.data_dir
cfg.dataset.data_files = inval_cved_filename
cfg.dataset.test_size = 0.3
# cfg.dataset.dev_size = 0.2
cfg.dataset.seed = 3247616750
cfg.dataset.shuffle = True
cfg.model.model_name_or_path = "entelecheia/ekonelectra-base-discriminator"
cfg.trainer.num_train_epochs = 10
cfg.trainer.max_seq_length = 512
cfg.trainer.train_batch_size = 48
cfg.trainer.eval_batch_size = 48
sm_inval = SimpleClassification(**cfg)
time: 2.71 s (started: 2023-01-05 05:35:55 +00:00)
sm_inval.train()
sm_inval.eval()
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and test with ratio 0.3
INFO:ekorpkit.datasets.config:Shuffling the dataframe with seed 3247616750
INFO:ekorpkit.datasets.config:Train data: (583, 6)
INFO:ekorpkit.datasets.config:Test data: (251, 6)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_512_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_cved-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_512_2_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.6306696415194301, 'tp': 157, 'tn': 55, 'fp': 24, 'fn': 15, 'auroc': 0.9269208124816014, 'auprc': 0.9689162568358742, 'acc': 0.8446215139442231, 'eval_loss': 0.4127258360385895}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_cved/configs/esg_topic_invalid_cved(2)_config.yaml
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_cved-classification
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [-2.01194334 2.78077936]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_cved/esg_topic_invalid_cved(2)_preds.parquet
Accuracy: 0.8446215139442231
Precison: 0.8416924252477069
Recall: 0.8446215139442231
F1 Score: 0.8419096206765615
Model Report:
___________________________________________________
precision recall f1-score support
Discarded 0.79 0.70 0.74 79
Validated 0.87 0.91 0.89 172
accuracy 0.84 251
macro avg 0.83 0.80 0.81 251
weighted avg 0.84 0.84 0.84 251
INFO:ekorpkit.visualize.base:Saved figure to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_cved/esg_topic_invalid_cved(2)_confusion_matrix.png
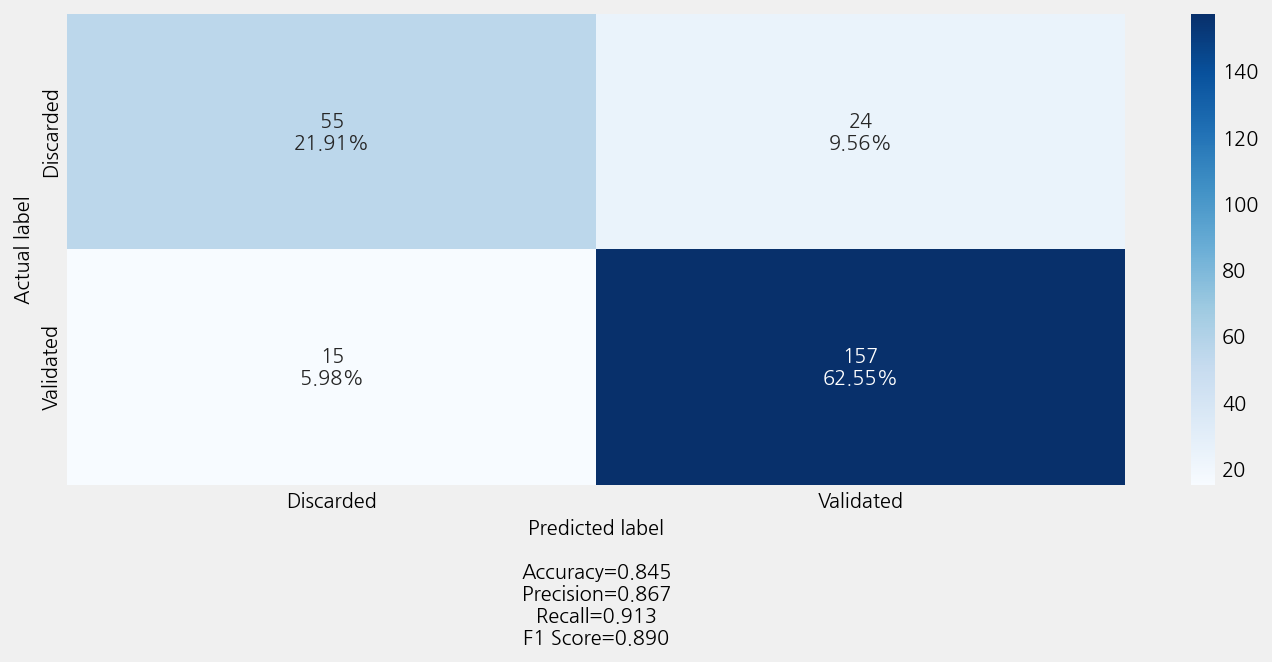
time: 1min 56s (started: 2023-01-05 05:35:57 +00:00)
Filter out invalid topics#
cfg = eKonf.compose("dataset=dataset")
cfg.name = "esg_topics_improved"
cfg.data_dir = "/workspace/data/datasets/simple"
ds_tp = Dataset(**cfg)
labels = list(ds_tp.splits['train'].labels.unique())
print(labels, len(labels), ds_tp.num_rows)
INFO:ekorpkit.info.column:index: index, index of data: index, columns: ['id', 'text', 'labels', 'class', 'example_id', 'count', 'split'], id: ['id']
INFO:ekorpkit.info.column:Adding id [split] to ['id']
INFO:ekorpkit.info.column:Added id [split], now ['id', 'split']
INFO:ekorpkit.info.column:Added a column [split] with value [train]
INFO:ekorpkit.info.column:Added a column [split] with value [dev]
INFO:ekorpkit.info.column:Added a column [split] with value [test]
INFO:ekorpkit.io.file:Concatenating 3 dataframes
INFO:ekorpkit.io.file:Concatenating 3 dataframes
['S-기업(공급망)동반성장/상생', 'G-지배구조', 'G-기업윤리/불공정/소송', 'S-소비자', 'E-환경혁신', 'S-사회공헌', 'S-고용', 'E-환경영향', 'E-기후변화', 'S-재해/안전관리'] 10 11054
time: 1.05 s (started: 2023-01-05 06:39:06 +00:00)
ds_tp_predicted = sm_inval.predict(ds_tp.data)
INFO:ekorpkit.io.file:Concatenating 3 dataframes
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [-2.00303316 2.70836926]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_cved/esg_topic_invalid_cved(2)_preds.parquet
time: 55.7 s (started: 2023-01-05 06:39:13 +00:00)
# select only validated data with pred_probs > 0.6
print(ds_tp.data.shape)
ds_tp_valid = ds_tp_predicted[(ds_tp_predicted.pred_labels == "Validated") & (ds_tp_predicted.pred_probs > 0.6)]
print(ds_tp_valid.shape)
print(ds_tp_valid.labels.value_counts())
INFO:ekorpkit.io.file:Concatenating 3 dataframes
(11054, 7)
(7951, 10)
S-소비자 1900
S-고용 1290
G-지배구조 1169
G-기업윤리/불공정/소송 807
S-사회공헌 616
E-환경혁신 571
E-환경영향 479
E-기후변화 474
S-재해/안전관리 339
S-기업(공급망)동반성장/상생 306
Name: labels, dtype: int64
time: 13.2 ms (started: 2023-01-05 06:40:09 +00:00)
file = ws.project_dir / "esg/outputs/esg_topic_labels/esg_topic_labels(0)_export.parquet"
tp_add = eKonf.load_data(file)
# exclude UNKNOWN and ESG
tp_add = tp_add[~tp_add["labels"].isin(["UNKNOWN", "ESG"])]
# combine tp_add and ds_tp_valid with ['text', 'labels'] columns only
ds_tp_merged = eKonf.concat_data([ds_tp_valid[['text', 'labels']], tp_add[['text', 'labels']]], axis=0)
print(ds_tp_merged.shape)
print(ds_tp_merged.labels.value_counts())
# Save data
valid_topic_file = "esg_topic_labels_validated.parquet"
valid_data_dir = ws.project_dir / "esg/data/esg_topic_validated"
eKonf.save_data(ds_tp_merged, valid_topic_file, valid_data_dir)
INFO:ekorpkit.io.file:Concatenating 2 dataframes
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_topic_validated/esg_topic_labels_validated.parquet
(8291, 2)
S-소비자 1914
S-고용 1310
G-지배구조 1235
G-기업윤리/불공정/소송 864
E-환경혁신 643
S-사회공헌 627
E-기후변화 527
E-환경영향 484
S-재해/안전관리 348
S-기업(공급망)동반성장/상생 339
Name: labels, dtype: int64
time: 485 ms (started: 2023-01-05 06:40:09 +00:00)
Training further on the additional topic data#
from ekorpkit.models.transformer.simple import SimpleClassification
valid_topic_file = "esg_topic_labels_validated.parquet"
valid_data_dir = ws.project_dir / "esg/data/esg_topic_validated"
cfg = eKonf.compose('task=simple.classification')
cfg.name = "esg_topics_validated"
cfg.dataset.data_dir = valid_data_dir
cfg.dataset.data_files = valid_topic_file
cfg.dataset.test_size = 0.3
cfg.dataset.shuffle = True
cfg.dataset.seed = 977634889
cfg.model.model_name_or_path = "entelecheia/ekonelectra-base-discriminator"
cfg.trainer.num_train_epochs = 10
cfg.trainer.max_seq_length = 256
cfg.trainer.train_batch_size = 128
cfg.trainer.eval_batch_size = 128
smt = SimpleClassification(**cfg)
Show code cell output
time: 2.8 s (started: 2023-01-05 06:40:09 +00:00)
cv_preds_topic = smt.cross_val_predict(cv=4, dev_size=0)
Show code cell output
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and test with ratio 0.3
INFO:ekorpkit.datasets.config:Shuffling the dataframe with seed 977634889
INFO:ekorpkit.datasets.config:Train data: (5803, 2)
INFO:ekorpkit.datasets.config:Test data: (2488, 2)
INFO:ekorpkit.io.file:Concatenating 2 dataframes
INFO:ekorpkit.datasets.config:Train data: (6218, 2)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_validated-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.771775144744973, 'acc': 0.8027013989387362, 'eval_loss': 0.7452939433210036}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/configs/esg_topics_validated(18)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 0
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_validated-classification
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 1.08960569 -1.41831708 1.00813735 -0.92140168 -0.8598122 -1.51699698
-1.43278515 0.25697005 -0.61077201 4.794034 ]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/esg_topics_validated(18)_preds.parquet
INFO:ekorpkit.datasets.config:Train data: (6218, 5)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_validated-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.7668444594100311, 'acc': 0.7978774722624216, 'eval_loss': 0.823479084407582}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/configs/esg_topics_validated(19)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 1
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 4.53867435 -0.85934401 1.3143158 -0.78634918 -0.51649958 -0.78543353
-1.25133133 -1.10254788 -1.0013324 1.03004241]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/esg_topics_validated(19)_preds.parquet
INFO:ekorpkit.datasets.config:Train data: (6218, 5)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_validated-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.7660671982418458, 'acc': 0.7973950795947902, 'eval_loss': 0.7515979970202726}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/configs/esg_topics_validated(20)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 2
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [-1.04944229 -0.43455282 -1.81818402 -0.32292348 0.09219684 5.79414225
-0.16078982 -0.41185176 -1.2190274 -1.59833586]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/esg_topics_validated(20)_preds.parquet
INFO:ekorpkit.datasets.config:Train data: (6219, 5)
INFO:ekorpkit.models.transformer.simple:No columns or data to rename
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_validated-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.774047705334313, 'acc': 0.8045366795366795, 'eval_loss': 0.7601279616355896}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/configs/esg_topics_validated(21)_config.yaml
INFO:ekorpkit.models.transformer.simple:Predicting split 3
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 4.52346754 -0.79634953 0.92594481 -0.75823683 -0.22142546 -0.65272802
-1.16158807 -1.07352436 -1.01481068 0.91516358]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/esg_topics_validated(21)_preds.parquet
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_validated/esg_topics_validated(21)_cv.parquet
time: 25min 38s (started: 2023-01-05 06:40:12 +00:00)
cols = ["text", "labels", "pred_labels", "raw_preds", "pred_probs"]
cv_preds_topic = cv_preds_topic[cols].reset_index()
time: 4.22 ms (started: 2023-01-05 07:53:37 +00:00)
records_with_label_error = smt.find_label_errors(cv_preds_topic, meta_columns=["index"])
print(len(records_with_label_error))
print(records_with_label_error[0])
# remove rows from preds that have label errors
data_topic_cved = cv_preds_topic.copy()
for record in records_with_label_error:
metadata = record.metadata
data_topic_cved = data_topic_cved[data_topic_cved.index != metadata["index"]]
print(len(data_topic_cved))
topic_cved_filename = "esg_topic_data_cved.parquet"
eKonf.save_data(data_topic_cved, topic_cved_filename, valid_data_dir)
INFO:ekorpkit.models.transformer.simple:Created 8291 records
366
text="신한은행 노조 ' 경영진 추가 화합 조치 필요 '\n신한은행 노동조합 ( 위원장 유주 선 ) 이 신한금융지주 신상훈 전 사장 의 추가적 인 명예회복 에 나서겠다고 밝혔다 .\n유주 선 신한은행 노조위원장 은 18 일 내일신문 과 전화 인터뷰 에서 ' 현 경영진 이 ( 신 전 사장 의 ) 명예 를 회복 시켜 드리기 위해서 추가적 인 화합 조치 를 내놔야 한다 ' 며 ' 노조 가 나서서 기회 가 있을 때 마다 경영진 에게 제안 을 하겠다 ' 고 말 했다 ." inputs={'text': "신한은행 노조 ' 경영진 추가 화합 조치 필요 '\n신한은행 노동조합 ( 위원장 유주 선 ) 이 신한금융지주 신상훈 전 사장 의 추가적 인 명예회복 에 나서겠다고 밝혔다 .\n유주 선 신한은행 노조위원장 은 18 일 내일신문 과 전화 인터뷰 에서 ' 현 경영진 이 ( 신 전 사장 의 ) 명예 를 회복 시켜 드리기 위해서 추가적 인 화합 조치 를 내놔야 한다 ' 며 ' 노조 가 나서서 기회 가 있을 때 마다 경영진 에게 제안 을 하겠다 ' 고 말 했다 ."} prediction=[('E-기후변화', 0.0010603860605236683), ('S-사회공헌', 0.0025242881090182714), ('E-환경영향', 0.000523405953129051), ('S-기업(공급망)동반성장/상생', 0.002255635923122306), ('G-지배구조', 0.0024603015855481497), ('S-고용', 0.9853566560115524), ('G-기업윤리/불공정/소송', 0.0022369285449255986), ('S-소비자', 0.001962865950724563), ('S-재해/안전관리', 0.0010000319093906645), ('E-환경혁신', 0.0006194999520653675)] prediction_agent=None annotation='G-지배구조' annotation_agent=None multi_label=False explanation=None id=None metadata={'index': 1887, 'label_error_candidate': 0} status='Validated' event_timestamp=None metrics=None search_keywords=None
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_topic_validated/esg_topic_data_cved.parquet
7925
time: 4.48 s (started: 2023-01-05 07:53:39 +00:00)
file = ws.project_dir / "esg/outputs/esg_topic_labels/esg_topic_labels(0)_export.parquet"
tp_add = eKonf.load_data(file)
# exclude UNKNOWN and ESG
tp_add = tp_add[~tp_add["labels"].isin(["UNKNOWN", "ESG"])]
# combine tp_add and ds_tp_valid with ['text', 'labels'] columns only
topic_cv_merged = eKonf.concat_data([data_topic_cved[['text', 'labels']], tp_add[['text', 'labels']]], axis=0)
print(topic_cv_merged.shape)
print(topic_cv_merged.labels.value_counts())
# Save data
topic_cved_filename = "esg_topic_data_cved_mreged.parquet"
eKonf.save_data(topic_cv_merged, topic_cved_filename, valid_data_dir)
INFO:ekorpkit.io.file:Concatenating 2 dataframes
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/esg_topic_validated/esg_topic_data_cved_mreged.parquet
(8265, 2)
S-소비자 1869
S-고용 1307
G-지배구조 1274
G-기업윤리/불공정/소송 870
E-환경혁신 673
S-사회공헌 611
E-기후변화 544
E-환경영향 428
S-기업(공급망)동반성장/상생 346
S-재해/안전관리 343
Name: labels, dtype: int64
time: 492 ms (started: 2023-01-05 07:53:43 +00:00)
from ekorpkit.models.transformer.simple import SimpleClassification
topic_cved_filename = "esg_topic_data_cved_mreged.parquet"
valid_data_dir = ws.project_dir / "esg/data/esg_topic_validated"
cfg = eKonf.compose('task=simple.classification')
cfg.name = "esg_topics_cved"
cfg.dataset.data_dir = valid_data_dir
cfg.dataset.data_files = topic_cved_filename
cfg.dataset.test_size = 0.2
cfg.dataset.dev_size = 0.2
cfg.dataset.shuffle = True
cfg.dataset.seed = 977634889
cfg.model.model_name_or_path = "entelecheia/ekonelectra-base-discriminator"
cfg.trainer.num_train_epochs = 10
cfg.trainer.max_seq_length = 256
cfg.trainer.train_batch_size = 128
cfg.trainer.eval_batch_size = 128
smt = SimpleClassification(**cfg)
time: 2.83 s (started: 2023-01-05 07:53:44 +00:00)
smt.train()
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and test with ratio 0.2
INFO:ekorpkit.datasets.config:Splitting the dataframe into train and dev with ratio 0.2
INFO:ekorpkit.datasets.config:Shuffling the dataframe with seed 977634889
INFO:ekorpkit.datasets.config:Train data: (5289, 2)
INFO:ekorpkit.datasets.config:Test data: (1653, 2)
INFO:ekorpkit.datasets.config:Dev data: (1323, 2)
Some weights of the model checkpoint at entelecheia/ekonelectra-base-discriminator were not used when initializing ElectraForSequenceClassification: ['discriminator_predictions.dense.weight', 'discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.bias']
- This IS expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ElectraForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of ElectraForSequenceClassification were not initialized from the model checkpoint at entelecheia/ekonelectra-base-discriminator and are newly initialized: ['classifier.out_proj.weight', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_train_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.4195900823409209, 'acc': 0.47543461829176115, 'eval_loss': 1.7749583721160889}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.6724554291746573, 'acc': 0.7127739984882842, 'eval_loss': 0.9586255116896196}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.749298248506891, 'acc': 0.783068783068783, 'eval_loss': 0.7731204032897949}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.7742315477284243, 'acc': 0.8049886621315193, 'eval_loss': 0.6826499429616061}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8042060041106648, 'acc': 0.8306878306878307, 'eval_loss': 0.6483639587055553}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8084240469908484, 'acc': 0.8344671201814059, 'eval_loss': 0.6348272562026978}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8041757582507306, 'acc': 0.8306878306878307, 'eval_loss': 0.6424735730344598}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.805954927572994, 'acc': 0.8321995464852607, 'eval_loss': 0.6535684954036366}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8067716627733474, 'acc': 0.8329554043839759, 'eval_loss': 0.6609686613082886}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8094637852091993, 'acc': 0.8352229780801209, 'eval_loss': 0.6675720485773954}
INFO:simpletransformers.classification.classification_model: Training of electra model complete. Saved to /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_cved-classification.
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file /workspace/.cache/cached_dev_electra_256_10_2
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
INFO:simpletransformers.classification.classification_model:{'mcc': 0.8075116052276107, 'acc': 0.8330308529945554, 'eval_loss': 0.6560884118080139}
INFO:ekorpkit.config:Saving config to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_cved/configs/esg_topics_cved(4)_config.yaml
time: 6min 14s (started: 2023-01-05 07:53:47 +00:00)
smt.model.eval.visualize.plot.confusion_matrix.include_values = False
smt.model.eval.visualize.plot.confusion_matrix.include_percentages = False
smt.model.eval.visualize.plot.figure.figsize = (12,10)
smt.eval()
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_cved-classification/best_model
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [-0.76133126 -1.24045217 -0.90773559 1.68788004 -1.41476214 1.18595886
-1.29130387 2.0727551 1.57164252 -1.33854187]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_cved/esg_topics_cved(4)_preds.parquet
Accuracy: 0.8257713248638838
Precison: 0.8275765712628258
Recall: 0.8257713248638838
F1 Score: 0.8231304507724357
Model Report:
___________________________________________________
precision recall f1-score support
E-기후변화 0.80 0.85 0.82 118
E-환경영향 0.77 0.62 0.69 76
E-환경혁신 0.80 0.75 0.78 142
G-기업윤리/불공정/소송 0.85 0.74 0.79 180
G-지배구조 0.89 0.86 0.87 263
S-고용 0.87 0.90 0.89 265
S-기업(공급망)동반성장/상생 0.80 0.57 0.67 70
S-사회공헌 0.76 0.88 0.82 118
S-소비자 0.79 0.92 0.85 355
S-재해/안전관리 0.88 0.68 0.77 66
accuracy 0.83 1653
macro avg 0.82 0.78 0.79 1653
weighted avg 0.83 0.83 0.82 1653
INFO:ekorpkit.visualize.base:Saved figure to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_cved/esg_topics_cved(4)_confusion_matrix.png
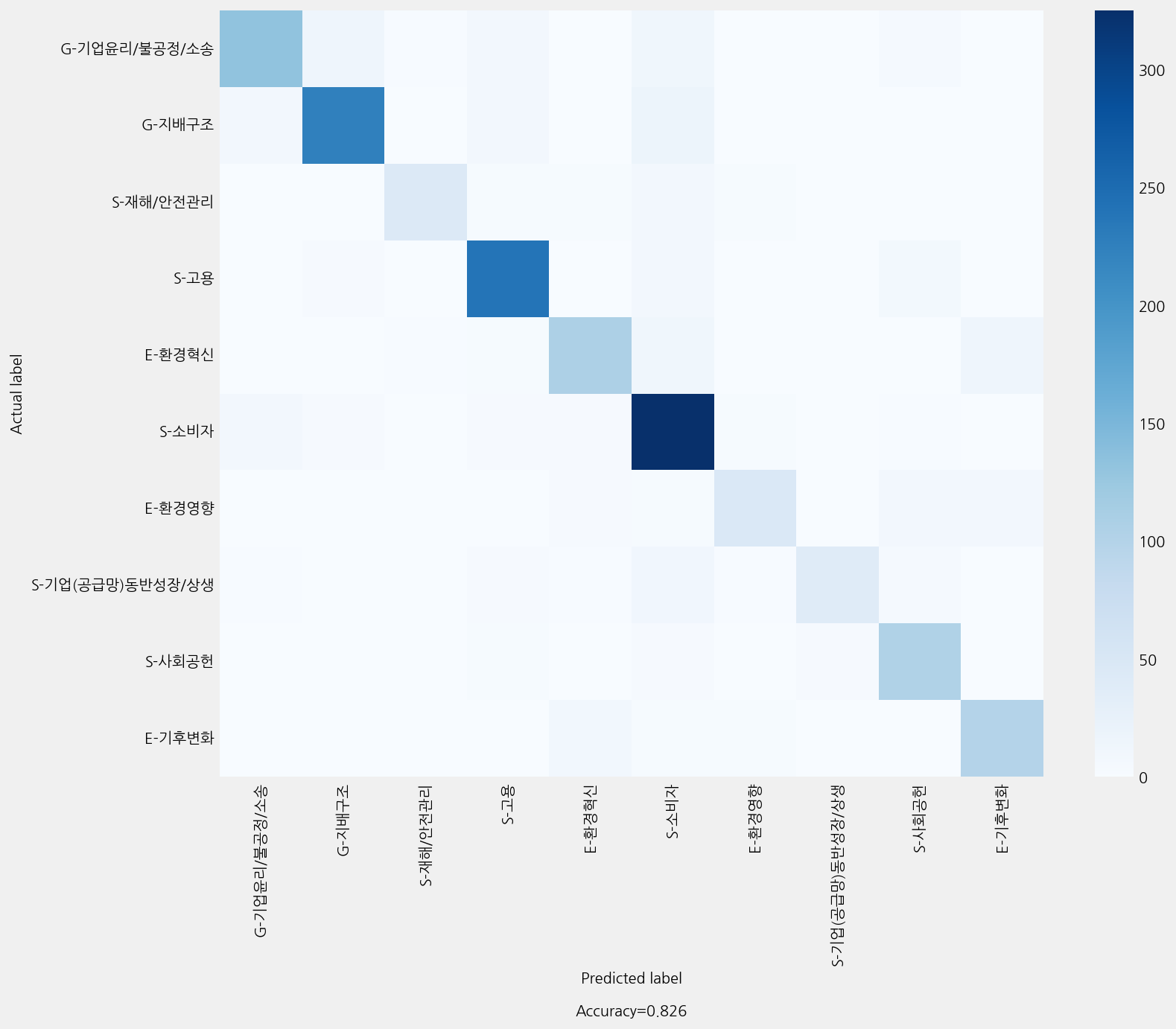
time: 5.6 s (started: 2023-01-05 08:00:02 +00:00)
Load data to predict#
news_data_dir = ws.project_dir / "esg/data/econ_news_kr/news_slice"
chunk_data = eKonf.load_data(
"econ_news_kr_chunks_*_20220911.parquet", news_data_dir, concatenate=True
)
print(chunk_data.shape)
chunk_data.head()
(1833910, 3)
| text | chunk_id | filename | |
|---|---|---|---|
| 0 | ■ 이슈 & 피플 (1일 오전 11시 30분) 신축년 새해가 밝았다 팬데믹이라는... | 0 | 02100101.20210101002609003.txt |
| 1 | 코로나19 팬데믹을 이겨내리라는 희망을 갖는 신축년(辛丑年) 소의 해다 근면, ... | 0 | 02100101.20210101002610001.txt |
| 2 | 정부는 금년도 경제성장률 전망을 3 2% 정도로 봤다 이대로만 되면 상대적으로 ... | 0 | 02100101.20210101002615001.txt |
| 3 | ◆ 신년기획 2021 경제기상도 / 해외경제 전망 ◆ 코로나19로 최악의 터널을 ... | 0 | 02100101.20210101040137001.txt |
| 4 | ◆ 신년기획 2021 경제기상도 / 해외경제 전망 ◆ 중국 경제는 2021년 더욱... | 0 | 02100101.20210101040138001.txt |
time: 13.6 s (started: 2023-01-05 08:00:07 +00:00)
chunk_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1833910 entries, 0 to 785336
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 text object
1 chunk_id int64
2 filename object
dtypes: int64(1), object(2)
memory usage: 56.0+ MB
time: 3.93 ms (started: 2022-12-29 10:49:56 +00:00)
Load company code info#
cfg = eKonf.compose("io/loader=plaintext_parser")
cfg.data_dir = news_data_dir
cfg.data_sources = "econ_news_kr_chunks_*_20221229.txt"
cfg.data.item = dict(filename="filename", codes="codes")
cfg.parser.split = True
cfg.parser.data_key = "codes"
cfg.parser.progress_per = None
code_info = eKonf.load_data(**cfg)
code_info.tail()
INFO:ekorpkit.io.load.data:==> processing 1/3 files <==
INFO:ekorpkit.io.parse.json:Number of data in the contents: 110689
INFO:ekorpkit.io.load.data:==> processing 2/3 files <==
INFO:ekorpkit.io.parse.json:Number of data in the contents: 281398
INFO:ekorpkit.io.load.data:==> processing 3/3 files <==
INFO:ekorpkit.io.parse.json:Number of data in the contents: 251404
{'filename': 'econ_news_kr_chunks_2022_code_20221229.txt', 'codes': '02100101.20220101002520005,1,005380'}
| filename | codes | |
|---|---|---|
| 643486 | econ_news_kr_chunks_2020_code_20221229.txt | 02100851.20201231140203001,0,001680 |
| 643487 | econ_news_kr_chunks_2020_code_20221229.txt | 02100851.20201231141813001,0,001750 |
| 643488 | econ_news_kr_chunks_2020_code_20221229.txt | 02100851.20201231164457001,0,000660 |
| 643489 | econ_news_kr_chunks_2020_code_20221229.txt | 02100851.20201231171734001,0,006360 |
| 643490 | econ_news_kr_chunks_2020_code_20221229.txt | 02100851.20201231204324001,0,068270 |
time: 1min (started: 2022-12-29 10:50:06 +00:00)
code_info_available = code_info.copy()
code_info_available["filename"] = code_info_available.codes.str[:26] + ".txt"
code_info_available["codes"] = code_info_available.codes.str[27:]
code_info_available["codes"] = code_info_available.codes.str.split(",")
code_info_available["chunk_id"] = code_info_available.codes.apply(lambda x: int(x[0]))
code_info_available["codes"] = code_info_available.codes.apply(lambda x: x[1:])
code_info_available["num_codes"] = code_info_available["codes"].apply(len)
code_info_available = code_info_available.explode("codes").reset_index(drop=True)
time: 2.63 s (started: 2022-12-29 10:51:16 +00:00)
len(code_info_available.codes.unique())
2275
time: 54.1 ms (started: 2022-12-29 10:51:20 +00:00)
code_info_available = code_info.copy()
code_info_available["filename"] = code_info_available.codes.str[:26] + ".txt"
code_info_available["codes"] = code_info_available.codes.str[27:]
code_info_available["codes"] = code_info_available.codes.str.split(",")
code_info_available["chunk_id"] = code_info_available.codes.apply(lambda x: int(x[0]))
code_info_available["codes"] = code_info_available.codes.apply(lambda x: x[1:])
code_info_available["num_codes"] = code_info_available["codes"].apply(len)
code_info_available = code_info_available.explode("codes").reset_index(drop=True)
eKonf.save_data(code_info_available, "econ_news_code_info_available_20221229.parquet", news_data_dir)
print(code_info_available.shape)
code_info_available.info()
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/econ_news_kr/news_slice/econ_news_code_info_available_20221229.parquet
(694599, 4)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 694599 entries, 0 to 694598
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 filename 694599 non-null object
1 codes 694599 non-null object
2 chunk_id 694599 non-null int64
3 num_codes 694599 non-null int64
dtypes: int64(2), object(2)
memory usage: 21.2+ MB
time: 3.12 s (started: 2022-12-29 10:51:46 +00:00)
filtered_data = chunk_data.merge(
code_info_available, on=["filename", "chunk_id"], how="inner"
)
cols = ["filename", "chunk_id", "text", "codes"]
filtered_data = filtered_data[cols]
eKonf.save_data(filtered_data, "econ_news_filtered_202201229.parquet", news_data_dir)
print(filtered_data.shape)
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/econ_news_kr/news_slice/econ_news_filtered_202201229.parquet
(718453, 4)
time: 1min 7s (started: 2022-12-29 10:52:00 +00:00)
Filter out invalid data#
from ekorpkit.models.transformer.simple import SimpleClassification
cfg = eKonf.compose("task=simple.classification")
cfg.name = "esg_topic_invalid_cved"
cfg.model.model_name_or_path = f"{cfg.path.model_dir}/{cfg.name}-classification"
sm_inval = SimpleClassification(**cfg)
sm_inval.load_model(sm_inval.model.model_name_or_path)
2022-12-29 10:53:25.970902: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topic_invalid_cved-classification
time: 7.21 s (started: 2022-12-29 10:53:25 +00:00)
invalid_preds_df = sm_inval.predict(filtered_data)
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 2.32296014 -2.33493686]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topic_invalid_cved/esg_topic_invalid_cved(2)_preds.parquet
time: 1h 30min 23s (started: 2022-12-29 10:53:38 +00:00)
cols = ["filename", "chunk_id", "text", "codes"]
valid_data = invalid_preds_df[invalid_preds_df.pred_labels == "Validated"][cols]
print(valid_data.shape)
filename = "esg_news_valid_20221229.parquet"
eKonf.save_data(valid_data, filename, news_data_dir)
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/econ_news_kr/news_slice/esg_news_valid_20221229.parquet
(558923, 4)
time: 1min 3s (started: 2022-12-29 12:24:02 +00:00)
news_data_dir = ws.project_dir / "esg/data/econ_news_kr/news_slice"
filename = "esg_news_valid_20221229.parquet"
valid_data = eKonf.load_data(filename, news_data_dir)
cols = ["text", "filename", "chunk_id", "codes"]
valid_data[cols].head()
| text | filename | chunk_id | codes | |
|---|---|---|---|---|
| 0 | ◆ 2020 경제기상도 / 업종별 전망 (반도체) ◆ 지난해 미·중 무역분쟁과 공... | 02100101.20200101040200001.txt | 0 | 000660 |
| 2 | ◆ 2020 경제기상도 / 업종별 전망 (가전) ◆ TV, 냉장고, 세탁기 등 전... | 02100101.20200101040200002.txt | 0 | 066570 |
| 3 | ◆ 2020 경제기상도 / 업종별 전망 (가전) ◆ TV, 냉장고, 세탁기 등 전... | 02100101.20200101040200002.txt | 0 | 005930 |
| 4 | ◆ 2020 경제기상도 / 업종별 전망 (디스플레이) ◆ 액정표시장치(LCD) 시... | 02100101.20200101040201001.txt | 0 | 034220 |
| 5 | 디스플레이 업계 등에서는 삼성과 LG가 글로벌 디스플레이 시장에서 중국 업체의 L... | 02100101.20200101040201001.txt | 1 | 003550 |
time: 7 s (started: 2022-12-29 12:25:05 +00:00)
Predict polarities#
from ekorpkit.models.transformer.simple import SimpleClassification
cfg = eKonf.compose("task=simple.classification")
cfg.name = "esg_polarity_validated"
cfg.model.model_name_or_path = f"{cfg.path.model_dir}/{cfg.name}-classification"
sm_pol = SimpleClassification(**cfg)
sm_pol.load_model(sm_pol.model.model_name_or_path)
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_polarity_validated-classification
time: 4.78 s (started: 2022-12-29 12:25:12 +00:00)
polarity_preds = sm_pol.predict(valid_data)
filename = "esg_news_polarity_20221229.parquet"
eKonf.save_data(polarity_preds, filename, news_data_dir)
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [ 5.97624731 -3.2472682 -2.35304332]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_polarity_validated/esg_polarity_validated(5)_preds.parquet
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/econ_news_kr/news_slice/esg_news_polarity_20221229.parquet
time: 36min 51s (started: 2022-12-29 12:25:17 +00:00)
Predicting categories#
from ekorpkit.models.transformer.simple import SimpleClassification
cfg = eKonf.compose("task=simple.classification")
cfg.name = "esg_topics_cved"
cfg.model.model_name_or_path = f"{cfg.path.model_dir}/{cfg.name}-classification"
sm_topic = SimpleClassification(**cfg)
sm_topic.load_model(sm_topic.model.model_name_or_path)
INFO:ekorpkit.models.transformer.simple:Loaded model from /workspace/projects/ekorpkit-book/exmaples/esg/models/esg_topics_cved-classification
time: 5.5 s (started: 2022-12-29 13:02:08 +00:00)
topic_preds = sm_topic.predict(valid_data)
filename = "esg_news_topic_20221229.parquet"
eKonf.save_data(topic_preds, filename, news_data_dir)
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:ekorpkit.models.transformer.simple:type of raw_outputs: <class 'numpy.ndarray'>
INFO:ekorpkit.models.transformer.simple:raw_output: [-0.37897453 -1.43046212 -0.97797042 -1.45200169 -1.20244873 0.19323829
-0.10120457 4.33574057 -1.0516876 1.75735104]
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/outputs/esg_topics_cved/esg_topics_cved(4)_preds.parquet
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/econ_news_kr/news_slice/esg_news_topic_20221229.parquet
time: 36min 47s (started: 2022-12-29 13:02:14 +00:00)
filename = "esg_news_topic_20221229.parquet"
topic_preds = eKonf.load_data(filename, news_data_dir)
filename = "esg_news_polarity_20221229.parquet"
polarity_preds = eKonf.load_data(filename, news_data_dir)
polarity_data = polarity_preds.rename(columns={"pred_labels": "polairty_preds"})[
["text", "filename", "chunk_id", "codes", "polairty_preds"]
]
esg_prediction_data = polarity_data.merge(
topic_preds.rename(columns={"pred_labels": "topic_preds"})[
["filename", "chunk_id", "codes", "topic_preds"]
],
on=["filename", "chunk_id", "codes"],
)
filename = "esg_news_prediction_results_20221229.parquet"
eKonf.save_data(esg_prediction_data, filename, news_data_dir)
INFO:ekorpkit.io.file:Saving dataframe to /workspace/projects/ekorpkit-book/exmaples/esg/data/econ_news_kr/news_slice/esg_news_prediction_results_20221229.parquet
time: 1min 22s (started: 2022-12-29 13:39:01 +00:00)
news_data_dir = ws.project_dir / "esg/data/econ_news_kr/news_slice"
filename = "esg_news_prediction_results_20221229.parquet"
esg_prediction_data = eKonf.load_data(filename, news_data_dir)
esg_prediction_data.tail(10)
| text | filename | chunk_id | codes | polairty_preds | topic_preds | |
|---|---|---|---|---|---|---|
| 668761 | 조현준 효성그룹 회장이 내년에는 호랑이처럼 민첩한 조직으로 변화할 것을 주문했다 ... | 02100851.20211231104409001.txt | 0 | 004800 | Neutral | G-지배구조 |
| 668762 | 미래에셋 "직원들 요청 있어" 내부선 인력유출 우려도 [사진=미래에셋증권] ... | 02100851.20211231112402001.txt | 0 | 006800 | Negative | S-고용 |
| 668763 | 중기부, '손실보상 선지급 금융 프로그램' 신설 방역지원금·방역물품지원금 등도 신... | 02100851.20211231112403001.txt | 0 | 001680 | Positive | S-사회공헌 |
| 668764 | 배재훈 HMM 대표가 코로나19로 인한 물류대란과 공급망 변화에 발 빠르게 대응해... | 02100851.20211231115157001.txt | 0 | 011200 | Neutral | E-환경혁신 |
| 668765 | 권칠승 중기부 장관[사진=중기부] 권칠승 중소벤처기업부 장관이 31일 신년사를 ... | 02100851.20211231143447001.txt | 0 | 001680 | Neutral | S-사회공헌 |
| 668766 | 해외 투지 공로…북미지역 내 소형 트랙터 수요 성장세 김희용 티와이엠(TYM) 회... | 02100851.20211231150933001.txt | 0 | 002900 | Positive | S-기업(공급망)동반성장/상생 |
| 668767 | SKT 952만·KT 615만·LG유플러스 446만 [사진=게티이미지뱅크 제공] ... | 02100851.20211231181802001.txt | 0 | 030200 | Neutral | S-소비자 |
| 668768 | 지난 8월에 삼성전자가 출시한 갤럭시Z폴드3와 갤럭시Z플립3 흥행도 5G 가입자 ... | 02100851.20211231181802001.txt | 1 | 005930 | Neutral | S-소비자 |
| 668769 | 올해 12년래 가장 큰 상승폭을 기록할 것으로 전망되고 있는 유가가 내년에도 계속... | 02100851.20211231182324001.txt | 0 | 267790 | Neutral | E-기후변화 |
| 668770 | 홍은택 카카오커머스 대표[사진=카카오커머스] 홍은택 카카오커머스 대표가 새해에 ... | 02100851.20211231210909001.txt | 0 | 035720 | Neutral | S-고용 |
time: 6.89 s (started: 2022-12-29 13:40:24 +00:00)
esg_prediction_data[esg_prediction_data.codes == "000020"]
| text | filename | chunk_id | codes | polairty_preds | topic_preds | |
|---|---|---|---|---|---|---|
| 7384 | 동국제약 '인사돌', 효능 논란 끝내고 정면승부로 성장세 동화약품 '잇치', 경쟁... | 02100851.20200108160505001.txt | 0 | 000020 | Neutral | S-소비자 |
| 32708 | [아시아경제 김민영 기자] 동화약품은 보통주 1주당 120원의 현금배당을 결정했다... | 02100801.20200224163725001.txt | 0 | 000020 | Neutral | G-지배구조 |
| 45877 | [코로나19 건강 지키기] 동화약품의 ‘판콜’은 지난해 매출 303억원을 기록한 ... | 02100311.20200326172754001.txt | 0 | 000020 | Neutral | S-소비자 |
| 47492 | 조선이 대한제국을 선포하기 보름 전인 1897년 9월 25일, 우리나라 최초의 제... | 02100601.20200320001516001.txt | 0 | 000020 | Neutral | S-사회공헌 |
| 62350 | 동화약품이 회사의 신약후보물질 DW2008을 신종 코로나바이러스 감염증(코로나19... | 02100101.20200421102241001.txt | 0 | 000020 | Neutral | S-소비자 |
| ... | ... | ... | ... | ... | ... | ... |
| 644089 | 구강유산균 시장이 빠르게 성장하고 있다 코로나19의 확산과 일상화된 마스크 사용... | 02100311.20211116142132001.txt | 0 | 000020 | Neutral | S-소비자 |
| 648607 | [아시아경제 서소정 기자] 동화약품의 기능성 화장품 '후시드 크림'은 최근 각광받... | 02100801.20211123210051001.txt | 0 | 000020 | Neutral | S-소비자 |
| 655548 | 롯데칠성음료의 ‘세상 맛있는 ZERO! 칠성사이다 ZERO!’편과 동화약품의 ‘달라... | 02100601.20211209160337001.txt | 5 | 000020 | Neutral | S-소비자 |
| 658637 | [사진=게티이미지뱅크] 동화약품 주가가 상승 중이다 1일 한국거래소에 따르... | 02100851.20211201094104001.txt | 0 | 000020 | Neutral | S-소비자 |
| 668090 | [사진=게티이미지뱅크] 동화약품 주가가 상승 중이다 22일 한국거래소에 따... | 02100851.20211222141644001.txt | 0 | 000020 | Neutral | S-소비자 |
176 rows × 6 columns
time: 42.6 ms (started: 2022-12-29 13:40:31 +00:00)
len(esg_prediction_data.codes.unique())
2273
time: 34.8 ms (started: 2022-12-29 13:40:31 +00:00)