FastText#
FastText is an open-source library for learning of word representations and sentence classification. It was introduced by [Bojanowski et al., 2016] in 2016.
FastText is an extension of word2vec that allows us to learn word representations for out-of-vocabulary words. It is based on the skip-gram model, but it uses character n-grams as its input and output instead of words.
Word2vec and GloVe are based on the words in the corpus. Even with a very large corpus, there are still words that are not present in the corpus.
Character n-grams#
Instead of using words to train the model, FastText uses character n-grams as its input and output.
Word embeddings are the average of the character n-grams that make up the word.
Less data is required to train the model, since the model is trained on character n-grams instead of words. A word can be its own context, yielding more information from the same amount of data.
For example, the word reading generates the following character n-grams:
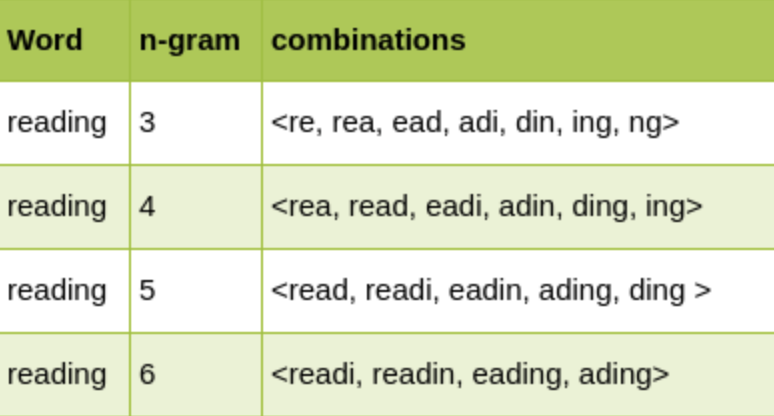
Angular brackets represent the start and end of a word.
Instead of using each unique n-gram as a feature, FastText uses the hash value of the n-gram as a feature. This reduces the number of features and makes the model more efficient.
Original paper uses a bucket size \(B\) of 2 million, and a hash function \(h\) that maps the n-gram to an integer in the range \([0, B)\).
Via hashing, each n-gram is mapped to a unique integer between 0 and 2 million.
The hash function is given by: \(h(w) = \text{hash}(w) \mod B\), where \(w\) is the n-gram and \(B\) is the bucket size.
Although the hash function is deterministic, it is not reversible. This means that the hash function cannot be used to recover the original n-gram.
The word
readingcan be represented by the following vector: \(\mathbf{v}_{reading} = \frac{1}{5} \sum_{i=1}^5 \mathbf{v}_{<rea>, <ead>, <adi>, <din>, <ing>}\)
Using FastText#
You can install FastText using the following command:
pip install fasttext
You can download the pre-trained FastText word vectors from the FastText website.
Format#
The first line of the file contains the number of words in the vocabulary and the size of the vectors. Each line contains a word followed by its vectors, like in the default fastText text format. Each value is space separated. Words are ordered by descending frequency. These text models can easily be loaded in Python using the following code:
import io
def load_vectors(fname):
fin = io.open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
n, d = map(int, fin.readline().split())
data = {}
for line in fin:
tokens = line.rstrip().split(' ')
data[tokens[0]] = map(float, tokens[1:])
return data
Training FastText#
FastText can be trained using the following command:
fasttext skipgram -input <input_file> -output <output_file>
Or you can use the following code:
import fasttext
# Skipgram model :
model = fasttext.train_unsupervised('data.txt', model='skipgram')
# or, cbow model :
model = fasttext.train_unsupervised('data.txt', model='cbow')
The returned model object represents your learned model, and you can use it to retrieve information.
print(model.words) # list of words in dictionary
print(model['king']) # get the vector of the word 'king'
Saving and loading a model object#
You can save your trained model object by calling the function save_model.
model.save_model("model_filename.bin")
and retrieve it later thanks to the function load_model:
model = fasttext.load_model("model_filename.bin")