Reinforcement Learning with Human Feedback (RLHF)#
Introduction#
Large Language Models (LLMs) have made significant progress in recent years.
LLMs can perform a wide range of natural language tasks such as translation, summarization, and question answering.
Prompt engineering is a process that enables LLMs to follow human instructions and provide useful responses.
Prompt engineering involves crafting a natural language prompt that guides the LLM to generate the desired response.
LLMs can provide useful responses to natural language queries in fields such as medicine, education, customer service, and more.
Large Language Models (LLMs) have made significant progress in recent years and are now capable of performing a wide range of natural language tasks, including following human instructions and providing useful responses.
Traditionally, LLMs were trained using language modeling, which involves predicting the next word(s) in a sentence given the previous context. However, recent advances in LLMs, such as GPT-3, have enabled them to perform more complex tasks, such as translation, summarization, and question answering.
Moreover, LLMs can now follow human instructions and provide useful responses through a process known as prompt engineering. Prompt engineering involves crafting a natural language prompt that guides the LLM to generate the desired response. This can be done by providing specific keywords, phrases, or examples in the prompt that the LLM can use to generate the response.
For example, an LLM trained on a large corpus of medical data can be prompted to generate a diagnosis for a patient based on their symptoms and medical history. The prompt could include key phrases such as “patient presents with fever and cough” or “patient has a history of heart disease.” The LLM can then generate a diagnosis based on its understanding of medical terminology and best practices.
LLMs can also provide useful responses to natural language queries. For example, an LLM trained on a large corpus of news articles can be prompted to provide a summary of a particular article or answer a specific question related to the article. The LLM can then generate a summary or answer based on its understanding of the content and context of the article.
Why Large Language Models (LLMs) use Reinforcement Learning#
Supervised learning only predicts ranks and doesn’t produce coherent responses.
Reinforcement Learning with Human Feedback (RLHF) is trained to estimate the quality of the produced response, rather than just the ranking score.
Cumulative rewards are necessary to enable coherent conversations, which Supervised Learning (SL) can’t provide.
SL only optimizes the token-level loss, which may not capture the coherence of the entire conversation.
Empirically, RLHF tends to perform better than SL.
LLMs like InstructGPT and ChatGPT use both Supervised Learning and Reinforcement Learning to attain optimal performance.
SL is used to learn the basic structure and content of the task, while RLHF is used to refine the model’s responses to improve accuracy.
Large Language Models (LLMs) use Reinforcement Learning (RL) in addition to Supervised Learning (SL) because RL enables the LLMs to learn from their own experience and optimize for a wide range of objectives. SL, on the other hand, requires large amounts of labeled data and can result in incoherent responses. RLHF is a particularly promising approach because it combines RL with human feedback to ensure that LLMs are aligned with human values and preferences. The combination of SL and RLHF is crucial for attaining optimal performance in LLMs, with SL used to learn the basic structure and content of the task, while RLHF is used to refine the model’s responses to improve accuracy. The “Capability vs. Alignment” framework highlights the importance of balancing the capabilities of LLMs with their alignment with human values and preferences, and RLHF can play a crucial role in achieving this balance.
Capability vs. Alignment#
“Capability vs. Alignment” is a framework for understanding risks associated with LLM development and deployment.
It emphasizes two dimensions of risk: capability and alignment.
Capability refers to the power and complexity of LLMs, which can generate realistic and coherent text, but may also pose risks such as generating misinformation.
Alignment refers to the extent to which LLM goals and values align with those of their human users.
There is a trade-off between capability and alignment, and balancing these two dimensions is crucial in LLM development and deployment.
Developers must pay attention to LLM alignment with human values, and take steps to mitigate potential risks associated with their capabilities.
This includes developing mechanisms for safety, transparency, and accountability, and engaging with stakeholders to ensure LLMs align with societal needs and concerns.
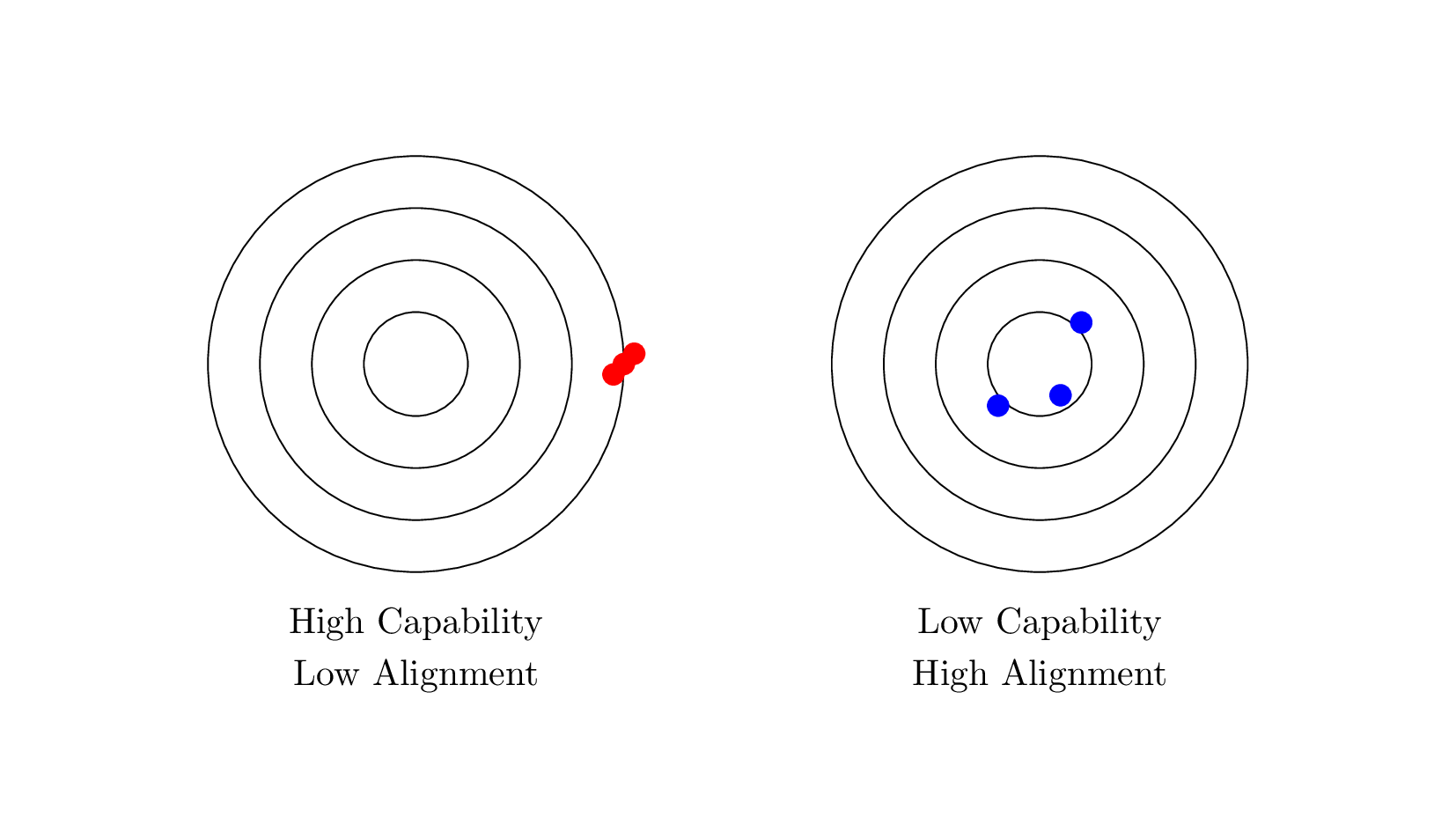
Fig. 131 Capability vs. Alignment#
“Capability vs. Alignment” is a framework for understanding the potential risks associated with the development and deployment of Large Language Models (LLMs), such as GPT-3.
Capability refers to the raw power and complexity of LLMs. LLMs can generate highly realistic and coherent text, and they can perform a wide range of natural language tasks, including translation, summarization, and question answering. However, this capability also comes with potential risks, such as the ability to generate misinformation or manipulate public opinion.
Alignment, on the other hand, refers to the extent to which the goals and values of LLMs align with those of their human users. If an LLM is not aligned with human values and preferences, it may generate responses that are harmful or malicious, even if they are highly realistic and coherent. Alignment is crucial to ensure that LLMs behave in a way that is safe, ethical, and beneficial to society.
The alignment problem in Large Language Models typically could cause the following problems:
LLMs may not follow the instructions given by the user.
LLMs may generate responses that are harmful or malicious, even if they are highly realistic and coherent.
It might be difficult for users to understand the reasoning behind the LLM’s responses.
The “Capability vs. Alignment” framework suggests that there is a trade-off between these two dimensions of risk. Increasing the capability of LLMs may come at the expense of alignment, and vice versa. For example, if an LLM is trained on large amounts of biased data, it may generate responses that perpetuate or amplify that bias, even if it is highly capable in other respects. Conversely, if an LLM is heavily constrained to ensure alignment, it may not be able to generate high-quality responses or perform certain tasks effectively.
The “Capability vs. Alignment” framework highlights the importance of balancing these two dimensions of risk when developing and deploying LLMs. It suggests that researchers and developers should pay close attention to the alignment of LLMs with human values and preferences, and should take steps to mitigate the potential risks associated with their capabilities. This includes developing robust mechanisms for ensuring safety, transparency, and accountability, and engaging with a broad range of stakeholders to ensure that LLMs are aligned with the needs and concerns of society as a whole.