LLM Application Architectures#
This lecture addresses the challenges and methods related to customization and fine-tuning of Large Language Models (LLMs), placing particular emphasis on their generative and predictive capacities. The discussion extends to the concept of ‘hallucination,’ which represents a significant hurdle in LLM applications. Solutions to this problem, particularly through contextual and relevant prompt engineering, are elaborated upon. The lecture also explores how the advent of vector stores, autonomous agents, and prompt pipelines has contributed to creating more contextualized and precise models.
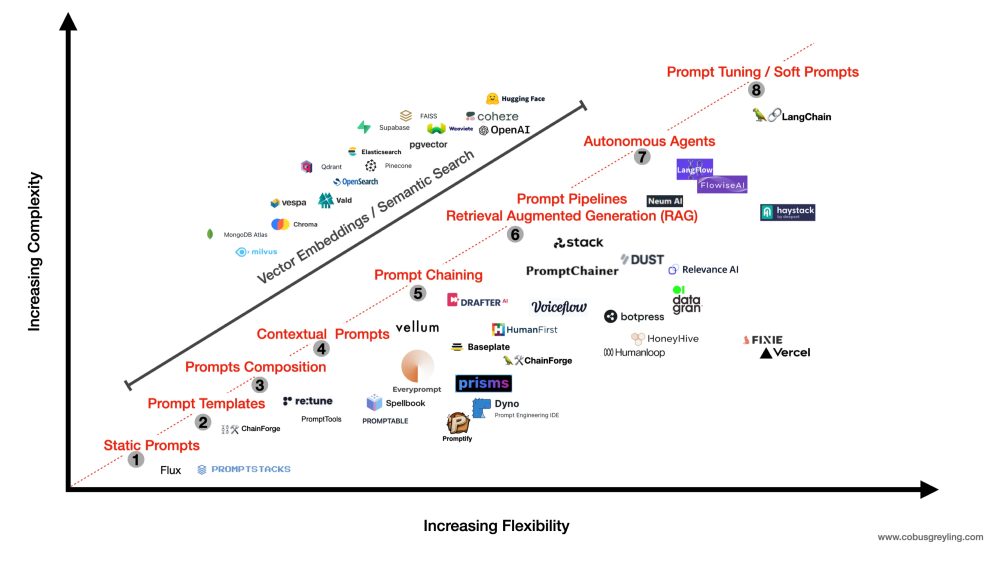
Challenges and Methods in Customizing LLMs#
Unstructured Nature of LLMs:
Human language is inherently unstructured, and so are the inputs and outputs in LLMs.
Prompt Engineering serves as the primary interface for such unstructured data.
Fine-Tuning in Early Approaches:
Originally seen as a way to make LLMs more domain-specific.
Problems:
Training data curation is both labor-intensive and expensive.
Fine-tuned models are time-stamped, limiting their adaptability.
Natural Language Understanding (NLU) models are often more efficient in classification tasks.
Generative vs. Predictive Power:
The generative aspect is more straightforward to utilize.
Contextual and concise data at inference-time reduces hallucinations, which are plausible but incorrect answers.
Solutions and Emerging Techniques#
Contextual Prompts at Inference-Time:
Proven to mitigate hallucination.
Involve chain-of-thought reasoning for better accuracy.
Role of Vector Stores/Databases:
Contribute to creating ‘few-shot’ prompts by providing contextual data snippets.
Autonomous Agents and Prompt Pipelines:
Engineer prompts based on real-time data, thus providing more context and relevance.
These autonomous systems offer adaptability compared to the more static prompt chaining methods.
Cross-Model Testing with Tools:
Tools like LangSmith and ChainForge enable testing different LLMs against a single prompt.
Allows for more effective enterprise-level implementation by selecting the most suitable model for specific tasks.
Terminology#
Prompt Engineering#
Prompt Engineering refers to the art and science of crafting effective prompts to guide the behavior of Large Language Models (LLMs) in generating desired outputs. This is a meta capability essential for unlocking the full potential of LLMs, which cannot be directly commanded or interacted with like chatbots. The technique involves envisioning the intended output and meticulously formulating a query or command to elicit that result.
Model Hallucination#
Model hallucination refers to the phenomenon where Large Language Models (LLMs) generate outputs that are plausible but factually incorrect. This often occurs when the model is confronted with ambiguous or uncertain scenarios. While the generated content may appear convincing, it diverges from factual accuracy.
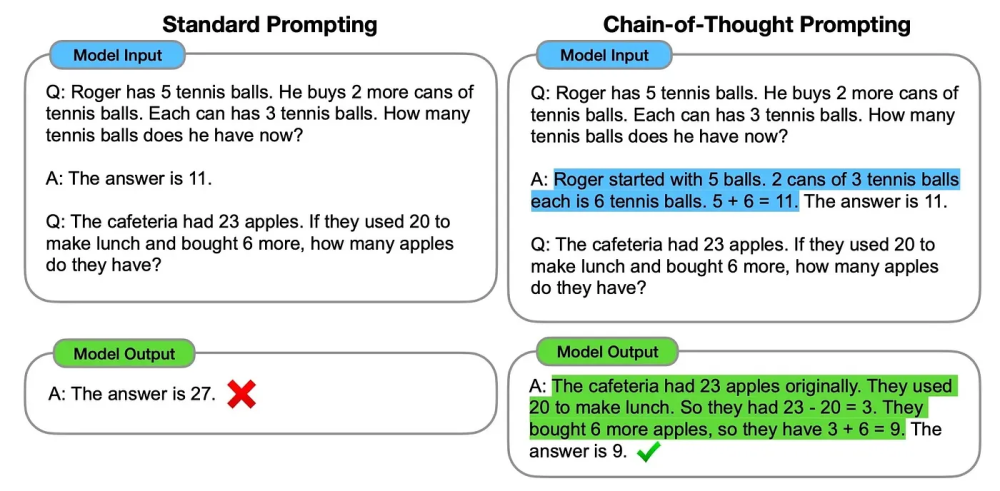
Chain-of-thought prompting#
Chain-of-thought prompting represents an advanced technique for interacting with Large Language Models (LLMs) to solve complex tasks, from arithmetic to common sense reasoning. This method deploys a sequence of carefully constructed prompts that guide the model through a logical process or “chain of thought,” thereby allowing it to generate more accurate and insightful outputs. The primary advantage of this approach is that it decomposes the input and output into manageable units, providing a window for detailed interpretation and modification.
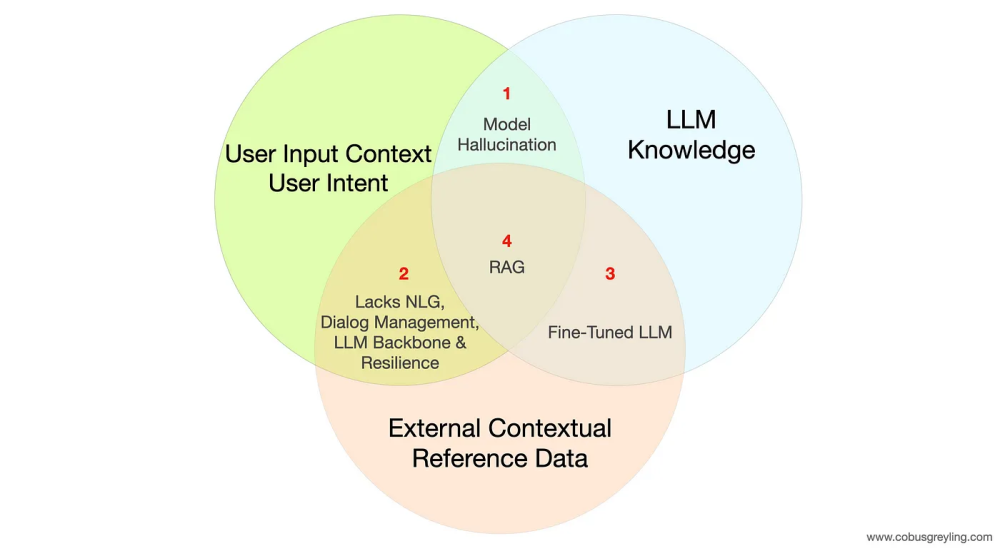
Retrieval Augmented Generation (RAG)#
Retrieval Augmented Generation (RAG) is a framework that integrates Large Language Models (LLMs) with external data sources for more contextually accurate responses. Three core components—User Input Context, LLM Knowledge, and External Contextual Reference Data—are involved. RAG serves as an intersection of these elements, aimed at overcoming the limitations of LLMs such as hallucination and the lack of real-time contextual data.
Prompt Chaining#
Prompt chaining involves the systematic arrangement and execution of a sequence of prompts to engage Large Language Models (LLMs) in multi-step or complex tasks. The process is facilitated via specialized visual programming User Interfaces (UIs) that allow for intricate customization and control. In a typical scenario, prompt chaining necessitates elements like data transformation, rule-based decision-making, and exception handling to deal with the inherently unstructured and unpredictable nature of LLM outputs.
Autonomous LLM Agents#
Autonomous LLM Agents employ Large Language Models (LLMs) to autonomously perform tasks by utilizing a set of tools and applying actions in a pre-defined or dynamic sequence. These agents use a “chain-of-thought” reasoning approach to decompose complex questions into smaller, manageable tasks. They possess the autonomy to decide the sequence of tools used, apply actions accordingly, and evaluate the sufficiency of the output. The concept extends to include Human-In-The-Loop tools and agent networks.
LLM Debugging and Monitoring#
LLM (Large Language Model) Debugging and Monitoring refer to the systematic procedures aimed at evaluating, analyzing, and improving the performance and behavior of LLMs. The emerging trend is to compare various LLMs against a common set of prompts, thereby enabling a nuanced understanding of model behavior. Tools like LangSmith and ChainForge facilitate these operations with functionalities such as prompt permutations, evaluation nodes, and visualization nodes.

Conclusion#
The customization and fine-tuning of LLMs have evolved beyond simple model training to more complex, context-aware methods. Contextual prompt engineering, facilitated by advanced tools like vector databases and autonomous agents, has proven effective in mitigating inherent challenges such as hallucination. These advancements signify a transition towards more adaptive and precise implementations of LLMs in enterprise environments.