Part-of-Speech Tagging and Parsing#
Introduction to Part-of-Speech (POS)#
The term “Part-of-Speech” refers to categories into which we can place words based on their syntactic role and behavior in a sentence. Examples include nouns, verbs, adjectives, adverbs, pronouns, prepositions, and conjunctions, among others.
For instance, consider the sentence “The quick brown fox jumps over the lazy dog.” Here, “fox” and “dog” are nouns, “quick” and “lazy” are adjectives, “jumps” is a verb, “over” is a preposition, and “the” is a determiner.
Each language has its own set of POS categories. For a more standardized approach, you might want to check out the Universal POS tags: Universal POS tags.
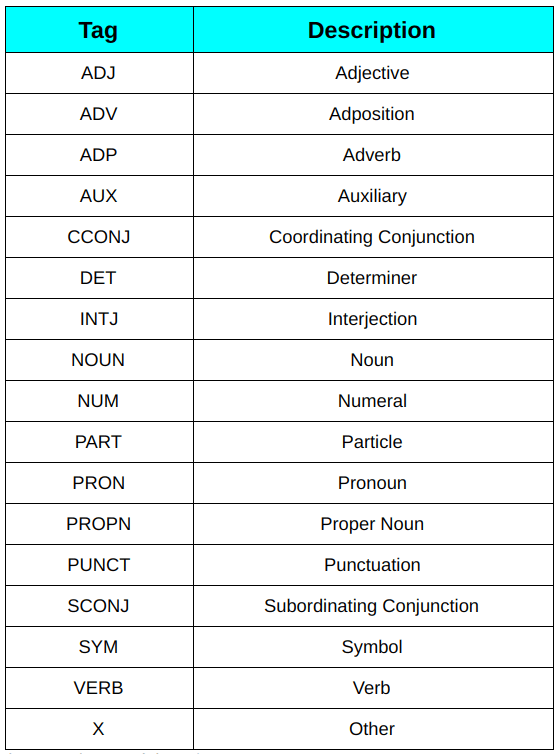
Fig. 73 List of Universal POS tags#
What is POS Tagging?#
POS tagging involves assigning a POS category to each word in a text based on both its meaning and context. This task is not as straightforward as it might seem due to the fact that words can serve different roles depending on their placement and function in a sentence.
For instance, consider the word “back” in the following contexts:
“The back door” - Here, “back” is an adjective.
“On my back” - Here, “back” is a noun.
“Win the voters back” - Here, “back” is a particle.
“Promised to back the bill” - Here, “back” is a verb.
Given the ambiguity and the existence of unknown words, we can’t rely solely on a dictionary for POS tagging.
Why Do We Need POS Tagging?#
POS tagging is a crucial step in many Natural Language Processing (NLP) tasks. It allows us to understand the basic structure of a sentence and plays a key role in syntactic parsing and information extraction.
Let’s take a look at how we can implement a POS tagger using the Python library spacy.
# !python -m spacy download en
import spacy
nlp = spacy.load("en_core_web_sm")
text = "POS tagging is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context."
for token in nlp(text):
print(token.text, "=>", token.pos_, "=>", token.tag_)
POS => PROPN => NNP
tagging => NOUN => NN
is => AUX => VBZ
the => DET => DT
process => NOUN => NN
of => ADP => IN
marking => VERB => VBG
up => ADP => RP
a => DET => DT
word => NOUN => NN
in => ADP => IN
a => DET => DT
text => NOUN => NN
( => PUNCT => -LRB-
corpus => PROPN => NNP
) => PUNCT => -RRB-
as => ADP => IN
corresponding => VERB => VBG
to => ADP => IN
a => DET => DT
particular => ADJ => JJ
part => NOUN => NN
of => ADP => IN
speech => NOUN => NN
, => PUNCT => ,
based => VERB => VBN
on => ADP => IN
both => CCONJ => CC
its => PRON => PRP$
definition => NOUN => NN
and => CCONJ => CC
its => PRON => PRP$
context => NOUN => NN
. => PUNCT => .
In the above script, we load the English language model (en_core_web_sm) from spacy. Then, we process a sentence through this model, which yields a Doc object. For each Token object in the Doc, we print its text along with its corresponding coarse-grained (pos_) and fine-grained (tag_) POS tags.
Dependency Parsing#
While POS tagging gives us information about the role of individual words in a sentence, dependency parsing helps us understand how these words interact with each other. In dependency parsing, we look for relationships between words: which word depends on which, and what’s the nature of this dependency.
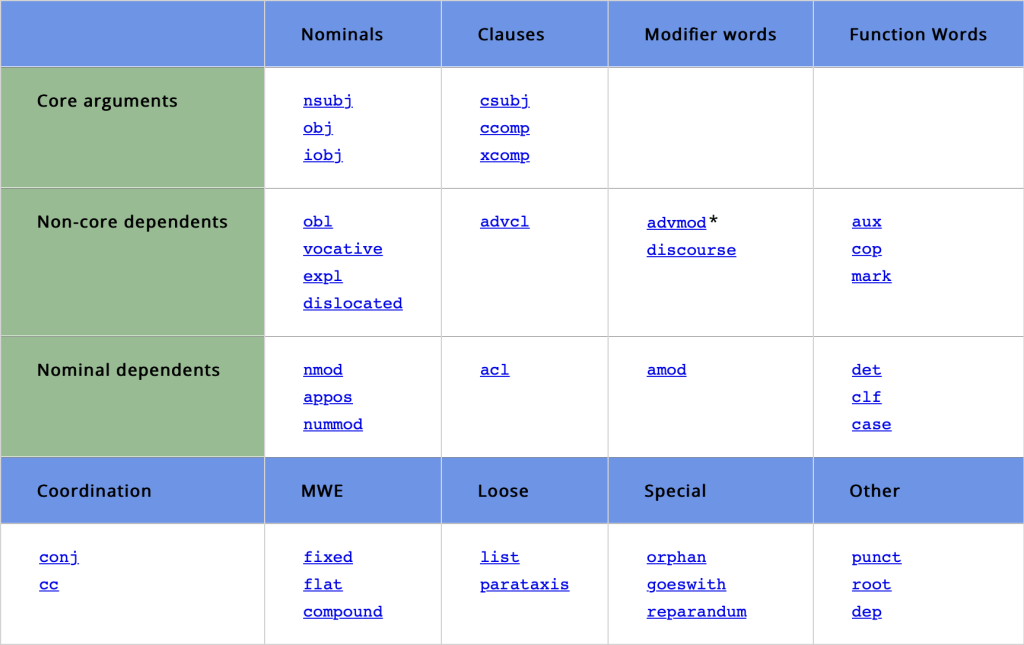
Fig. 74 Universal Dependency Relations#
Let’s visualize dependency parsing for our example sentence using spacy’s built-in displacy module:
from spacy import displacy
sent = "The quick brown fox jumps over the lazy dog."
displacy.render(nlp(sent), style='dep', jupyter=True)
The output of this script will be a graphical representation of words in the sentence and the grammatical relationships between them.
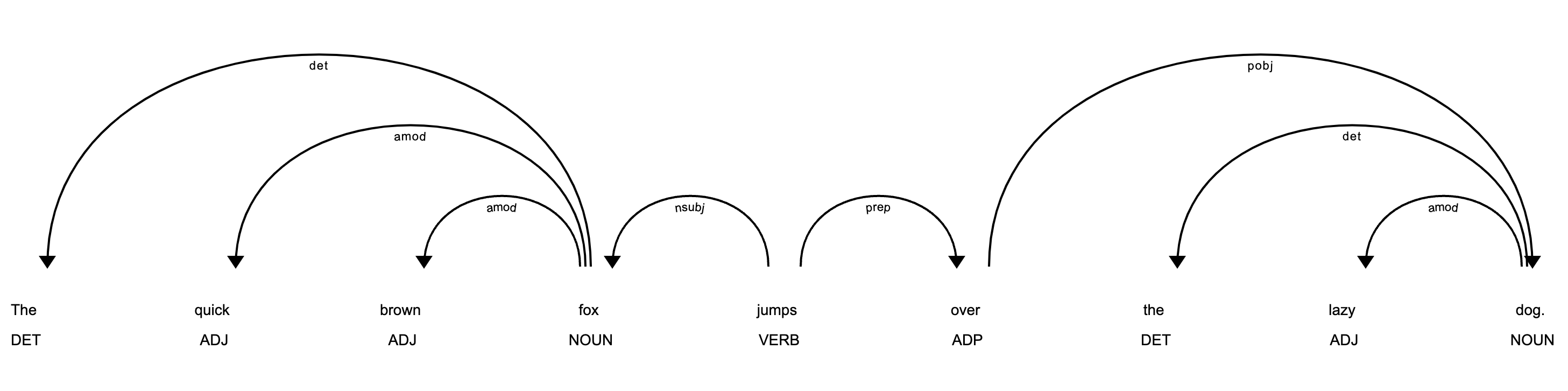
Fig. 75 Dependency parsing#
Constituency Parsing#
Unlike dependency parsing, which centers on the relationships between individual words, constituency parsing focuses on the sentence’s hierarchical structure. It breaks down the sentence into sub-phrases or constituents, each of which belongs to a specific category in the grammar of the language. Categories include noun phrase (NP), verb phrase (VP), etc.
In constituency parsing, sentences are often represented as constituency trees. For instance, the sentence “It took me more than two hours to translate a few pages of English.” might be broken down into the following sub-phrases: “It” (NP), “took me more than two hours to translate a few pages of English” (VP), and so on.
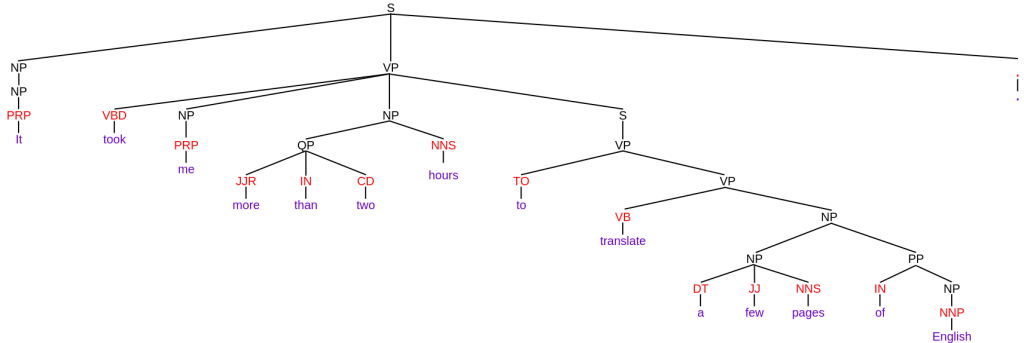
Fig. 76 Constituency parsing: “It took me more than two hours to translate a few pages of English.”#
As of now, constituency parsing is not directly supported by spaCy, but there are other libraries such as NLTK that do offer this feature.
Overall, POS tagging, dependency parsing, and constituency parsing play crucial roles in understanding the structure and meaning of text, and are key steps in many NLP applications.
Creating a POS Tagger#
Creating a Part-Of-Speech (POS) tagger is an essential task in Natural Language Processing (NLP). A POS tagger is a type of machine learning classifier that assigns a part-of-speech tag to each word in an input sentence or document. These tags provide crucial information about the role of each word in the sentence, which can greatly aid in tasks like parsing and entity recognition.
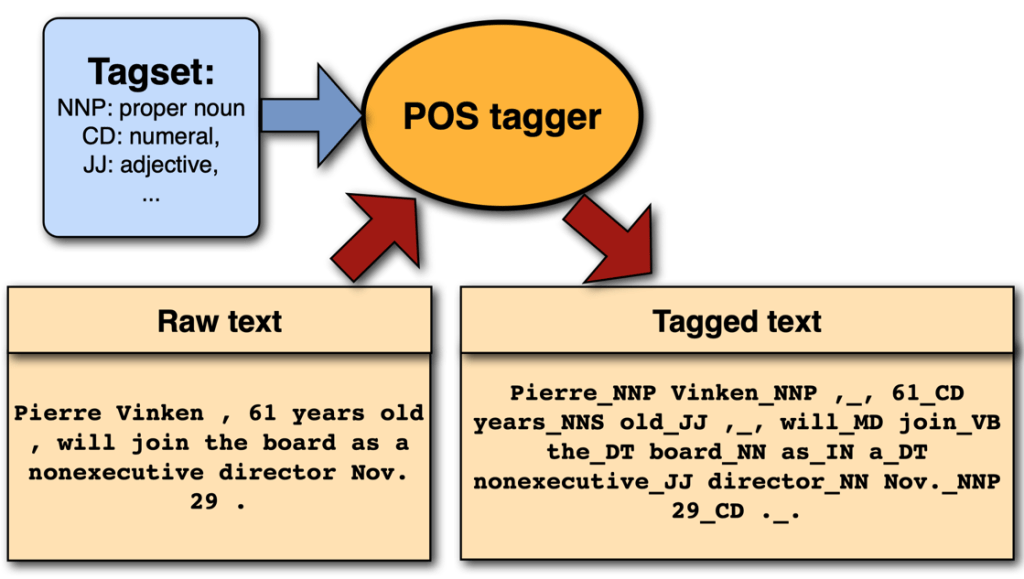
Fig. 77 POS tagger#
Creating a POS tagger involves the following steps:
1. Defining the Tag Set#
The first step is to decide on the set of tags that you’ll be using. These tags might include common parts of speech like ‘NOUN’, ‘VERB’, ‘ADJ’ (adjective), and ‘ADV’ (adverb), among others. Depending on your specific task, you might need a more detailed tag set, which includes tags for specific verb tenses or noun types, for instance.
2. Collecting and Annotating Data#
Next, you need to collect and annotate a large amount of text data with these POS tags. The exact amount of data you need will depend on the complexity of your task and the diversity of your tag set. More complex tasks and more diverse tag sets generally require more data.
If you’re creating a POS tagger for a new language or domain, you may need to do this annotation yourself, which can be a time-consuming process. If you’re working with an existing language or domain, you might be able to find an existing annotated corpus to use.
3. Choosing a Model#
Once you have your annotated data, you’ll need to choose a machine learning model for your POS tagger. Common choices include Hidden Markov Models (HMMs), Conditional Random Fields (CRFs), and more recently, neural networks, each with its strengths and weaknesses.
4. Training the Model#
Next, you’ll need to train your chosen model on your annotated data. This generally involves splitting your data into a training set and a validation set, training your model on the training set, and periodically evaluating its performance on the validation set.
5. Evaluating the Model#
After your model is trained, you’ll need to evaluate its performance on a separate test set to ensure that it generalizes well to new data. Common metrics for evaluating POS taggers include accuracy (the percentage of words that were assigned the correct tag) and F1 score (a weighted average of precision and recall).
6. Using and Updating the Model#
Finally, once your model is trained and evaluated, you can use it to tag new sentences! Over time, you may need to update your model as new words and usages emerge in the language.
Remember, creating a POS tagger is not a one-time task. It’s an ongoing process that requires regular updates and adjustments to keep up with changes in language use. But with the right approach, you can create a powerful tool that provides valuable insights into the structure and meaning of text.