T5: Text-To-Text Transfer Transformer#

“Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” [Raffel et al., 2020]
A unified framework that converts all text-based language problems into a text-to-text format by framing them as conditional text generation tasks.
Combining the pre-training objectives of BERT and GPT-2, T5 is trained on a very large number of tasks and is able to perform well on a wide range of tasks with minimal task-specific architecture modifications.
C4 (Corpus of Cleaned Web Crawled Text) is used as the training corpus, which is a large-scale dataset of 3.3 billion web pages.
Achieves state-of-the-art results on 11 out of 15 tasks in GLUE, SuperGLUE, and SQuAD v1.1.
T5: Text-to-Text Framework#
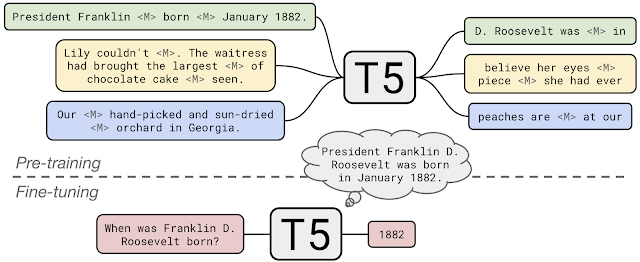
Unified Input & Output Format#
T5 means “
Text-To-TextTransferTransformer”.Every task considered by T5 is framed as a conditional text generation task with a single input and output sequence.
Translation:
translate English to German: How old are you?\(\rightarrow\)Wie alt bist du?Text classification:
classify sentiment: This movie is so bad.\(\rightarrow\)negativeText summarization:
summarize: The movie was not good. The animation and the graphics were good. This is a good movie.\(\rightarrow\)The movie was not good.MNLI (entailment):
mnli: Premise: A person on a horse jumps over a broken down airplane. Hypothesis: The person is training his horse for a competition.\(\rightarrow\)entailmentMNLI (neutral):
mnli: Premise: A person on a horse jumps over a broken down airplane. Hypothesis: The person is at the zoo, riding a horse.\(\rightarrow\)neutralRegression:
sts-b: The cat was playing in the garden. The cat was playing in the yard.\(\rightarrow\)5.0
C4: Colossal Clean Crawled Corpus#
Common Crawl#
Common Crawl is a web crawl data repository that contains petabytes of data collected from the public web.
It is a non-profit organization that collects data from the public web and makes it freely available to the research community.
It produces around 30TB of data per month.
However, Common Crawl contains large amounts of noisy data, such as error messages, spam, and duplicate content.
To address this problem, the authors of T5 use the C4 dataset, which is a cleaned version of Common Crawl.
Colossal Clean Crawled Corpus#
For C4, the authors took Common Crawl scrape from April 2019 and applied some cleansing filters on it:
Only retained lines that ended in a terminal punctuation mark (i.e. a period, exclamation mark, question mark, or end quotation mark).
Discarded any page with fewer than 5 sentences and only retained lines that contained at least 3 words.
Removed any page that contained any word on the
List of Dirty, Naughty, Obscene or Otherwise Bad Words.Removed any line with the word
Javascript.Removed any page where the phrase
lorem ipsumappeared.Removed any pages that contained a curly bracket.
Deduplicate the data set, discarded all but one of any three-sentence span occurring more than once in the data set.
Since most of the downstream tasks are focused on English-language text, langdetect is used to filter out any pages that were not classified as English with a probability of at least 0.99.
The filtered dataset is larger than most data sets used for pre-training (about 750 GB).
It also comprises reasonably clean and natural English text.
This data set is called the “Colossal Clean Crawled Corpus” (or C4 for short) and released as part of TensorFlow Datasets.
The Model#
Encoder-Decoder Transformer Model#
T5 uses the same encoder-decoder Transformer architecture as BERT.
However, a simplified layer normalization is used the activations are only rescaled and no additive bias is applied.
After layer normalization, a residual skip connection, originated from ResNet, adds each subcomponent’s input to its output.
Also, instead of using a fixed positional encoding, T5 uses a relative positional encoding.
Baseline#
The baseline model is designed so that the encoder and decoder are each similar in size and configuration to a BERT-base model.
Specifically, the encoder and decoder each have 12 layers, with about 220 million parameters.
The objective of the baseline model is to predict the dropped-out tokens in the input sequence.

A Systematic Study of Transfer Learning Methodology#
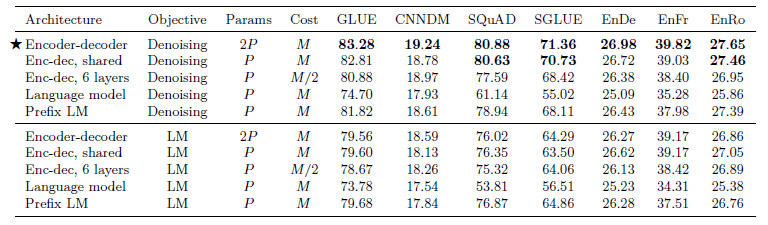
model architectures, where we found that encoder-decoder models generally outperformed “decoder-only” language models;pre-training objectives, where we confirmed that fill-in-the-blank-style denoising objectives (where the model is trained to recover missing words in the input) worked best and that the most important factor was the computational cost;unlabeled datasets, where we showed that training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;training strategies, where we found that multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task;and
scale, where we compare scaling up the model size, the training time, and the number of ensembled models to determine how to make the best use of fixed compute power.
Architectures#
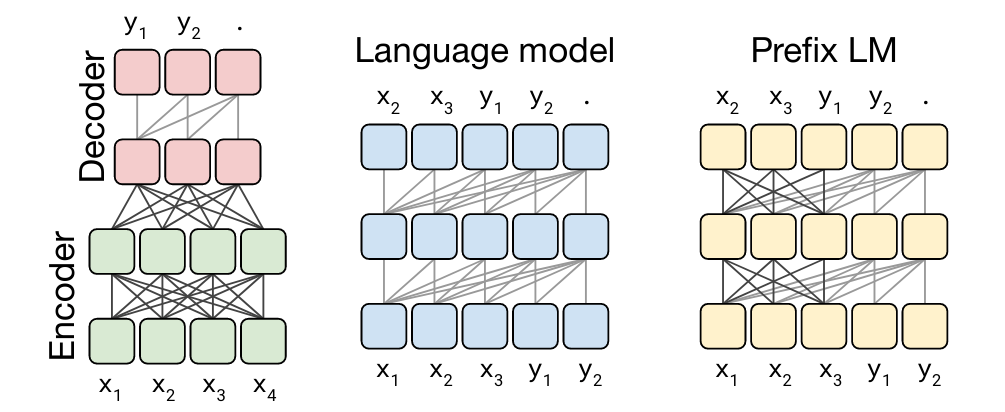
At an architectural level, there are several options in selecting the training approach:
Encoder-Decoder:
This is the standard encoder-decoder Transformer architecture.
Encoder is trained a BERT-style, fully visible language modeling objective. (i.e. every token contributes to the attention calculation of every other token)
Decoder is trained in a GPT-style, causal language modeling objective. (i.e. every token contributes to the attention calculation of every token that appears before it)
Language Model: This is essentially the causal attention language modeling objective.
Prefix Language Model: This is a combination of the BERT-style and language model approaches. For example, the taks of translating from English to German is framed as a prefix language model task, where the input
translate English to German:attended in BERT-style, and the outputWie alt bist du?is attended autoregressively.
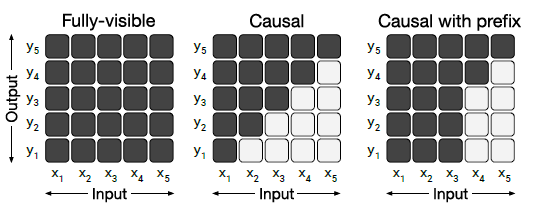
Unsupervised Objective#

With respect to the pre-training objective, authors have tested the following:
Language Modeling: This is the standard language modeling objective, where the model is trained to predict the next token in a sequence.
Deshuffling: This is a variant of language modeling, where the model is trained to predict the original order of a shuffled sequence.
Corrupting Spans: Masking a sequence of tokens and training the model to predict these masked tokens.

The BERT-style objective performs best, though the prefix language modeling objective attains similar performance on the translation tasks.


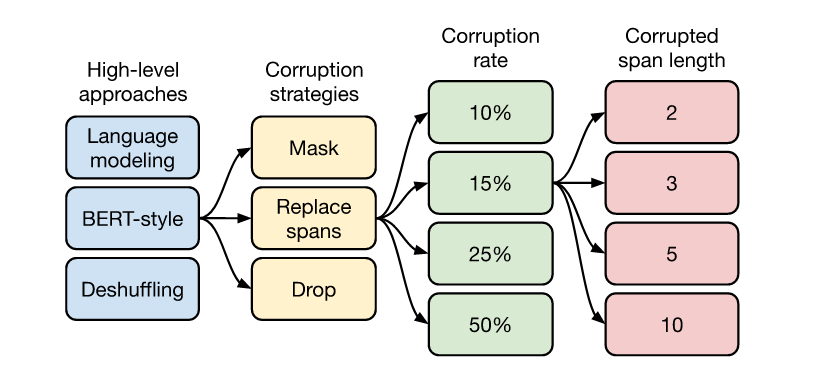
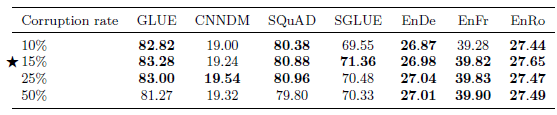
Corruption Rates#
Using a larger corruption rate results in longer targets, which can potentially slow down training.
Based on the results and the historical precedent set by BERT, a corruption rate of 15% is used going forward.
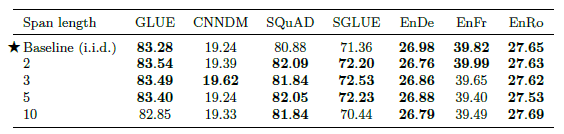
Corrupted Span Length#
When multiple consecutive tokens have been corrupted, they are treated as a “span” and a single unique mask token is used to replace the entire span.
A limited difference is found between these objectives, though the version with an average span length of 10 slightly underperforms the other values in some cases.
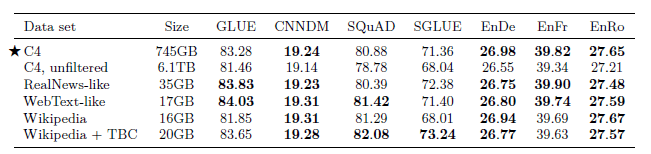
Unlabeled Datasets#
Different pretraining datasets are tried.
C4: The one mentioned in Section 2 in this story article.
C4, unfiltered: C4 but without filtering, to know the effect of the heuristic filtering
RealNews-like: C4 but only include content from one of the domains used in the “RealNews” data set.
WebText-like: Similarly, the WebText data set only uses content from webpages.
Wikipedia: English Wikipedia text data from TensorFlow Datasets.
Wikipedia+TBC: Toronto Books Corpus (TBC) contains text extracted from eBooks, combining with Wikipedia following BERT.
Pre-training on in-domain unlabeled data can improve performance on downstream tasks. (e.g.: unlabled news data helps downstream news dataset.) But this is unsatisfying if the goal is to pre-train a model that can rapidly adapt to language tasks from arbitrary domains.
Unlabeled Dataset Sizes#
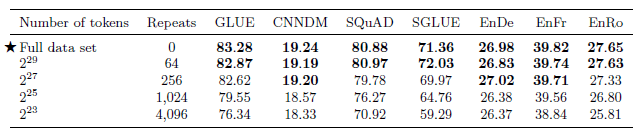
C4 has \(2^{35}\)= 34B tokens.
Truncated variants of C4 consisting of \(2^{29}\), \(2^{27}\), \(2^{25}\) and \(2^{23}\) tokens.
These sizes correspond to repeating the data set 64, 256, 1,024, and 4,096 times respectively over the course of pre-training.
As expected, performance degrades as the data set size shrinks.
Fine-Tuning Methods#
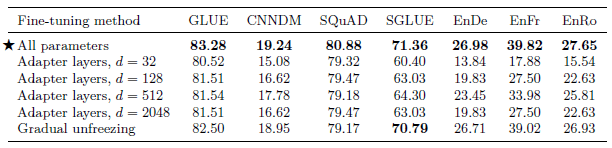
Fine-tuning all parameters.
Adapter Layers: keeping most of the original model fixed while fine-tuning. Adapter layers are additional dense-ReLU-dense blocks that are added after each of the preexisting feed-forward networks in each block of the Transformer.
Gradual Freezing: More and more of the model’s parameters are finetuned over time. At the start of fine-tuning, only the parameters of the final layer are updated, then after training for a certain number of updates the parameters of the second-to-last layer are also included, and so on until the entire network’s parameters are being fine-tuned.
It is found that gradual unfreezing caused a minor degradation in performance across all tasks, though it did provide some speedup during fine-tuning.
Multi-Task Learning#
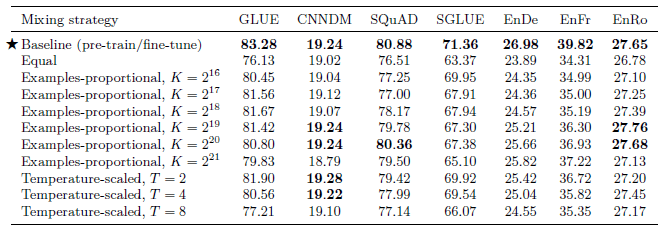
Multi-task learning is to train the model on multiple tasks at a time.
Multi-task learning underperforms pre-training followed by fine-tuning on most tasks.
Scaling#
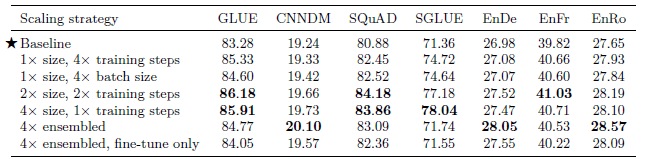
There are a variety of possible ways to scale, including using a bigger model, training the model for more steps, and ensembling.
There is no large difference between training a 2x bigger model for 2x as long and training a 4x bigger model on any of the tasks.
This suggests that increasing the training time and increasing the model size can be complementary means of improving performance.
The results also suggest that ensembling provides an orthogonal and effective means of improving performance through scale.
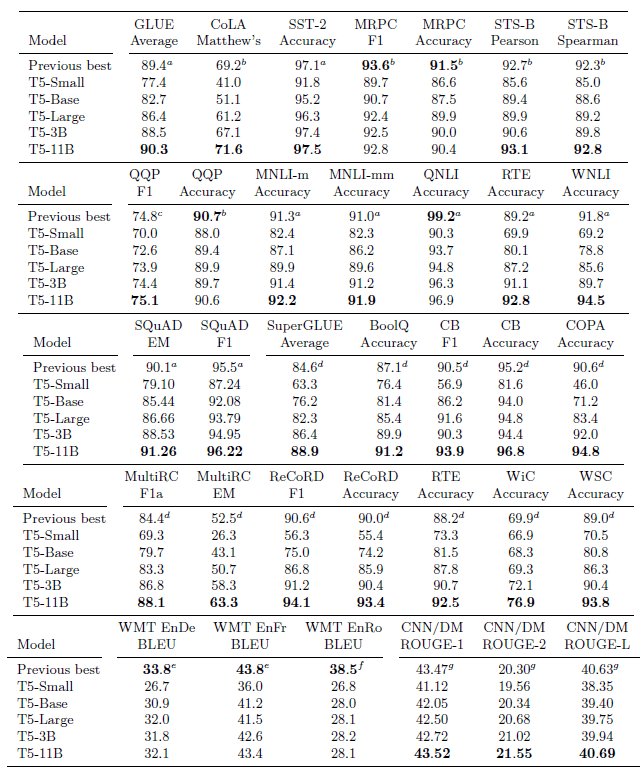
SOTA Comparisons#
Small, Base, Large, 3B, and 11B refer to model configurations with 60 million, 220 million, 770 million, 3 billion, and 11 billion parameters, respectively. (by tuning different hyperparameters.)
Overall, state-of-the-art performance is achieved on 18 out of the 24 tasks.
T5–3B model variant did beat the previous state of the art in a few tasks, but scaling the model size to 11 billion parameters was the most important ingredient for achieving the best performance.
For SQuAD, T5 outperformed the previous state-of-the-art ALBERT by over one point on the Exact Match score.
For SuperGLUE, T5 improved upon the state-of-the-art RoBERTa by a large margin from an average score of 84.6 to 88.9.
Further experiment is performed on three configurations as above:
The standard baseline model, which was pre-trained on 2²⁵=34B tokens.
Baseline-1T: The baseline trained instead for about 1 trillion tokens (i.e. the same amount of pre-training used for T5).
T5-Base.
T5-Base performs substantially better than Baseline-1T, suggesting that scale is not the only factor that contributes to T5’s success.
