Tokenization Pipeline#
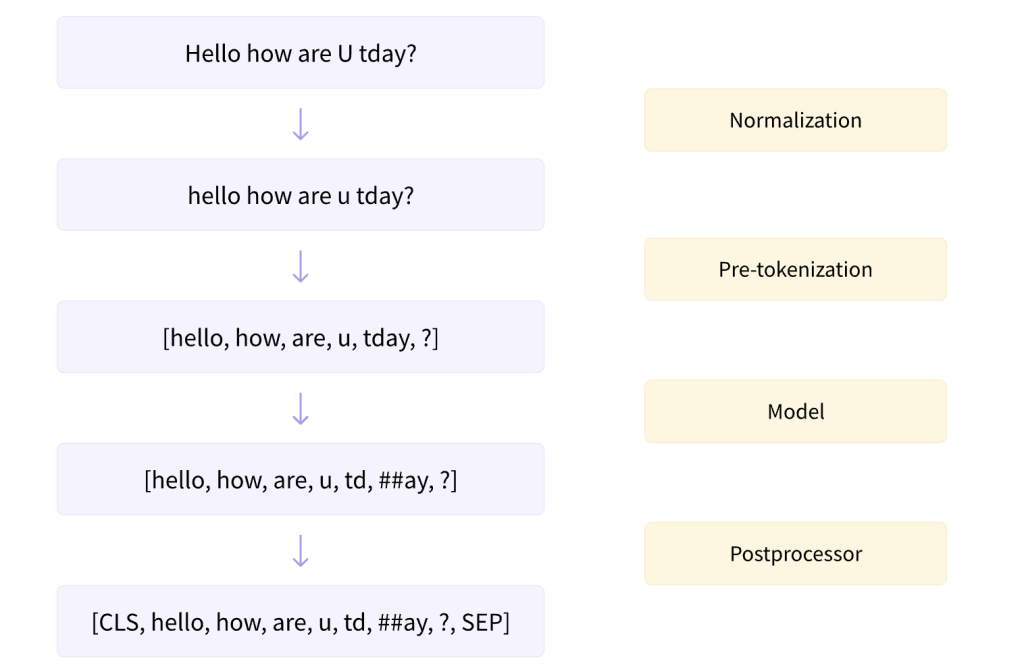
Fig. 130 Tokenization pipeline#
The tokenization process typically involves the following steps:
Normalization: This is the process of converting text into a standard format. This may involve converting all text to lowercase, removing punctuation or special characters, correcting spelling errors, and so on. The goal of normalization is to reduce the complexity of the text and to focus on the important features.
Pre-tokenization: This involves splitting the text into preliminary tokens. This could be as simple as splitting the text into words based on whitespace, or it could involve more complex processes like sentence segmentation.
Model: This is the core algorithm that determines how the pre-tokenized text is further broken down into tokens. There are various models available, including word-level, character-level, and subword-level tokenization models.
Post-processing: This involves any additional processing that needs to be done after tokenization. This could include removing stop words (common words like ‘is’, ‘the’, ‘and’, etc. that are often filtered out), stemming (reducing words to their root form), or lemmatization (reducing words to their base or dictionary form).
Let’s now look at how we can implement this pipeline using Python.
Implementing Tokenization in Python#
We will be using the transformers library from Hugging Face, which provides a wide range of pre-trained models for NLP tasks. It also provides various tokenizers that we can use.
First, let’s import the necessary libraries:
from transformers import AutoTokenizer
We can use the AutoTokenizer class to automatically infer the correct tokenizer to use based on the pre-trained model we specify.
Normalization#
Normalization is usually handled internally by the tokenizer. However, we can see the effect of normalization by directly calling the normalizer:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
hello how are u?
In this example, we’re using the tokenizer for the bert-base-uncased model. The normalize_str method applies the normalizer to the input string, converting all characters to lowercase and removing any special characters.
Unicode Normalization#
TL;DR
Use NFKC normalization to normalize your text before training your language model.
Unicode Normalization Forms
There are four normalization forms:
NFC: Normalization Form Canonical Composition
NFD: Normalization Form Canonical Decomposition
NFKC: Normalization Form Compatibility Composition
NFKD: Normalization Form Compatibility Decomposition
In the above forms, “C” stands for “Canonical” and “K” stands for “Compatibility”. The “C” forms are the most commonly used. The “K” forms are used when you need to convert characters to their compatibility representation. For example, the “K” forms will convert “fi” to “fi”.
There two main differences between the two sets of forms:
The length of the string is changed or not: NFC and NFKC always produce a string of the same length or shorter, while NFD and NFKD may produce a string that is longer.
The original string is changed or not: NFC and NFD always produce a string that is identical to the original string, while NFKC and NFKD may produce a string that is different from the original string.
Unicode Normalization in Python
In Python, you can use the unicodedata module to normalize your text. The unicodedata.normalize function takes two arguments:
form: The normalization form to use. This can be one of the following:NFC,NFD,NFKC,NFKD.unistr: The string to normalize.
import unicodedata
text = "abcABC123가나다…"
print(f"Original: {text}, {len(text)}")
for form in ["NFC", "NFD", "NFKC", "NFKD"]:
ntext = unicodedata.normalize(form, text)
print(f"{form}: {ntext}, {len(ntext)}")
Original: abcABC123가나다…, 13
NFC: abcABC123가나다…, 13
NFD: abcABC123가나다…, 16
NFKC: abcABC123가나다..., 15
NFKD: abcABC123가나다..., 18
Pre-tokenization#
Next, we perform pre-tokenization. This involves splitting the text into preliminary tokens:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
[('Hello', (0, 5)),
(',', (5, 6)),
('how', (7, 10)),
('are', (11, 14)),
('you', (16, 19)),
('?', (19, 20))]
Different models may use different pre-tokenization methods. For example, the GPT-2 and T5 models use different pre-tokenizers:
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
tokenizer = AutoTokenizer.from_pretrained("t5-small")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
[('▁Hello,', (0, 6)),
('▁how', (7, 10)),
('▁are', (11, 14)),
('▁you?', (16, 20))]
Model#
The model is the core algorithm that determines how the pre-tokenized text is further broken down into tokens. This is usually handled internally by the tokenizer, so we won’t go into detail here.
Post-processing#
Finally, we perform post-processing. This involves any additional processing that needs to be done after tokenization. For example, we might want to convert our tokens into input IDs, which can be inputted into our
model:
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
Downloading (…)/main/tokenizer.json: 100%|██████████| 1.36M/1.36M [00:00<00:00, 2.46MB/s]
[('Hello', (0, 5)),
(',', (5, 6)),
('Ġhow', (6, 10)),
('Ġare', (10, 14)),
('Ġ', (14, 15)),
('Ġyou', (15, 19)),
('?', (19, 20))]
In this example, we’re using the pre_tokenize_str method of the tokenizer’s model to tokenize the input string.
Postprocessing#
Postprocessing involves any additional processing that needs to be done after the text has been tokenized. This can include padding the tokenized text to a certain length, adding special tokens (like start and end tokens), or converting the tokenized text into a format that can be used by a machine learning model.
Here’s an example of how you can perform postprocessing using the transformers library:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("Hello, how are you?")
input_ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids
[7592, 1010, 2129, 2024, 2017, 1029]
In this example, the convert_tokens_to_ids method is used to convert each token into its corresponding input ID.
Another common post-processing step is adding special tokens, such as [CLS] and [SEP], which are used by models like BERT:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("Hello, how are you?")
tokens = ["[CLS]"] + tokens + ["[SEP]"]
tokens
['[CLS]', 'hello', ',', 'how', 'are', 'you', '?', '[SEP]']
In this example, we manually add the [CLS] token at the beginning of our token list and the [SEP] token at the end.
However, the transformers library provides a more convenient way to perform these post-processing steps:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
encoded_input = tokenizer("Hello, how are you?", add_special_tokens=True)
encoded_input
{'input_ids': [101, 7592, 1010, 2129, 2024, 2017, 1029, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
In this example, the tokenizer method automatically tokenizes the input text, converts the tokens to input IDs, and adds the special tokens. The add_special_tokens=True argument specifies that we want to add the special tokens.
The tokenizer method returns an Encoding object, which contains all the information we need:
print(encoded_input.input_ids) # The input IDs
print(encoded_input.token_type_ids) # The token type IDs
print(encoded_input.attention_mask) # The attention mask
[101, 7592, 1010, 2129, 2024, 2017, 1029, 102]
[0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 1]
The input_ids attribute contains the input IDs, the token_type_ids attribute contains the token type IDs (used for models that have separate segments of input, like BERT), and the attention_mask attribute contains the attention mask (used for models that use attention, like BERT and GPT-2).