mC4 Dataset#
by Xue et al. [2020]
The mC4 dataset is a multilingual colossal, cleaned version of Common Crawl’s web crawl corpus, which is based on the Common Crawl dataset. The dataset includes 108 languages and is specifically designed to pretrain language models and word representations. This dataset is an extension of the C4 dataset, which was designed to be English-only.
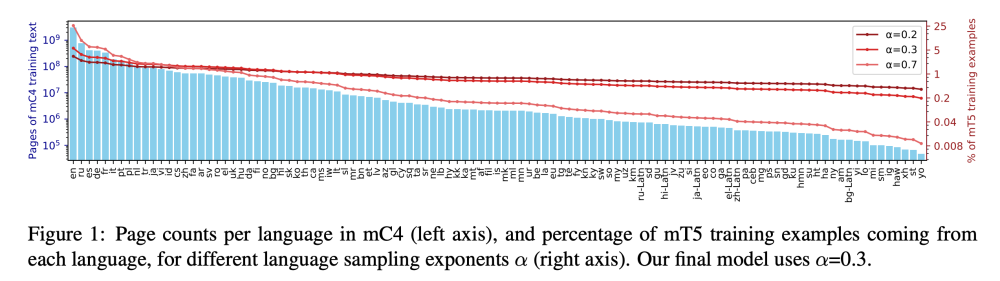
Fig. 128 mC4 Dataset#
Dataset Construction#
To build the mC4 dataset, the authors made use of all the 71 monthly web scrapes released so far by Common Crawl, which is dramatically more source data than was used for C4. They used cld3 to identify over 100 languages and applied several filtering steps, such as line length filter and deduplication, to clean and preprocess the data. After the filtering steps, they grouped the remaining pages by language and included all languages with 10,000 or more pages in the final dataset.
Building the Dataset#
To build the mC4 dataset, follow these steps:
Collect data from the Common Crawl dataset by making use of all 71 monthly web scrapes.
Use cld3 to identify over 100 languages.
Apply a line length filter that requires pages to contain at least three lines of text with 200 or more characters.
Deduplicate lines across documents and remove pages containing bad words.
Detect each page’s primary language using cld3 and remove those with a confidence below 70%.
Group the remaining pages by language and include in the corpus all languages with 10,000 or more pages.
After completing these steps, you’ll have the mC4 dataset, which contains text in 107 languages as defined by cld3.
Comparison to Related Models#
Most related models use Wikipedia as their primary source for multilingual data. However, some models, such as XLM-R and mBART, also leverage data from Common Crawl to expand their training dataset. The mC4 dataset, in contrast, focuses on using data from Common Crawl with a more extensive filtering and cleaning process.
mBERT#
mBERT (Devlin, 2018) is a multilingual version of BERT (Devlin et al., 2019). The primary difference between mBERT and BERT is the training set. While BERT is trained on English Wikipedia and the Toronto Books Corpus, mBERT is trained on up to 104 languages from Wikipedia.
XLM#
XLM (Conneau and Lample, 2019) is based on BERT but applies improved methods for pre-training multilingual language models, including explicitly cross-lingual pre-training objectives. The most massively-multilingual variant of XLM was trained on 100 languages from Wikipedia.
XLM-R#
XLM-R (Conneau et al., 2020) is an improved version of XLM based on the RoBERTa model (Liu et al., 2019). XLM-R is trained with a cross-lingual masked language modeling objective on data in 100 languages from Common Crawl. To improve the pre-training data quality, pages from Common Crawl were filtered by an n-gram language model trained on Wikipedia (Wenzek et al., 2020).
mBART#
mBART (Liu et al., 2020a) is a multilingual encoder-decoder model based on BART (Lewis et al., 2020b). mBART is trained with a combination of span masking and sentence shuffling objectives on a subset of 25 languages from the same data as XLM-R.
MARGE#
MARGE (Lewis et al., 2020a) is a multilingual encoder-decoder model trained to reconstruct a document in one language by retrieving documents in other languages. It uses data in 26 languages from Wikipedia and CC-News (Liu et al., 2019).
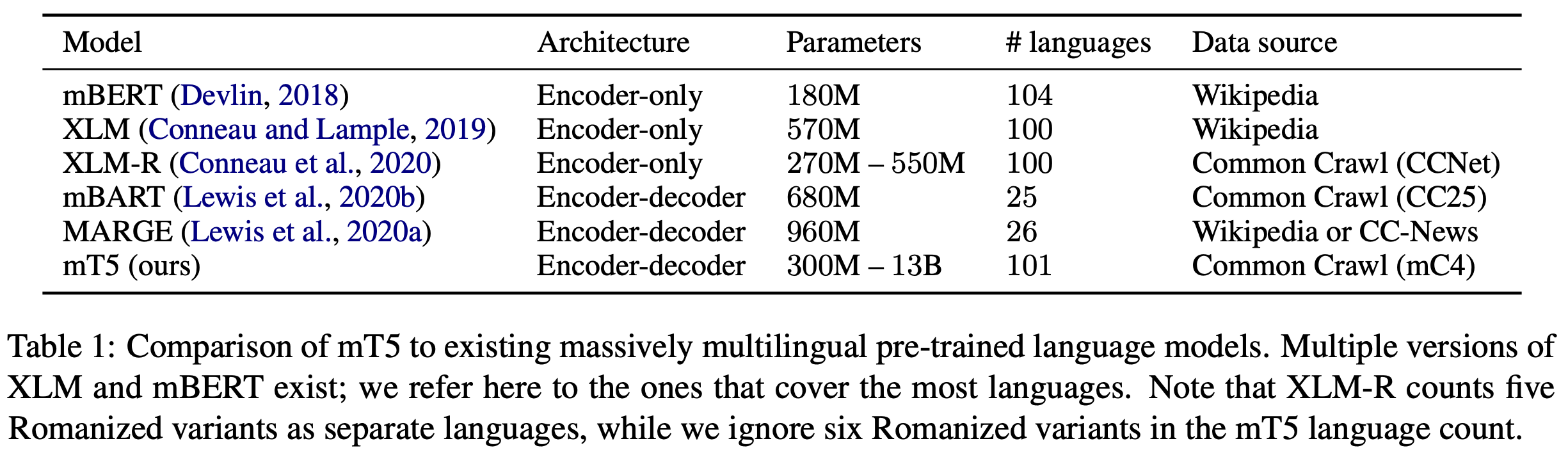
Fig. 129 Comparison of mC4 and other datasets#
Data Description#
The dataset includes the following fields:
url: URL of the source as a string
text: Text content as a string
timestamp: Timestamp as a string
Supported Languages#
The mC4 dataset supports 108 languages, including languages written in the Latin script (denoted by “-Latn”).
language code |
language name |
|---|---|
af |
Afrikaans |
am |
Amharic |
ar |
Arabic |
az |
Azerbaijani |
be |
Belarusian |
bg |
Bulgarian |
bg-Latn |
Bulgarian (Latin) |
bn |
Bangla |
ca |
Catalan |
ceb |
Cebuano |
co |
Corsican |
cs |
Czech |
cy |
Welsh |
da |
Danish |
de |
German |
el |
Greek |
el-Latn |
Greek (Latin) |
en |
English |
eo |
Esperanto |
es |
Spanish |
et |
Estonian |
eu |
Basque |
fa |
Persian |
fi |
Finnish |
fil |
Filipino |
fr |
French |
fy |
Western Frisian |
ga |
Irish |
gd |
Scottish Gaelic |
gl |
Galician |
gu |
Gujarati |
ha |
Hausa |
haw |
Hawaiian |
hi |
Hindi |
hi-Latn |
Hindi (Latin script) |
hmn |
Hmong, Mong |
ht |
Haitian |
hu |
Hungarian |
hy |
Armenian |
id |
Indonesian |
ig |
Igbo |
is |
Icelandic |
it |
Italian |
iw |
former Hebrew |
ja |
Japanese |
ja-Latn |
Japanese (Latin) |
jv |
Javanese |
ka |
Georgian |
kk |
Kazakh |
km |
Khmer |
kn |
Kannada |
ko |
Korean |
ku |
Kurdish |
ky |
Kyrgyz |
la |
Latin |
lb |
Luxembourgish |
lo |
Lao |
lt |
Lithuanian |
lv |
Latvian |
mg |
Malagasy |
mi |
Maori |
mk |
Macedonian |
ml |
Malayalam |
mn |
Mongolian |
mr |
Marathi |
ms |
Malay |
mt |
Maltese |
my |
Burmese |
ne |
Nepali |
nl |
Dutch |
no |
Norwegian |
ny |
Nyanja |
pa |
Punjabi |
pl |
Polish |
ps |
Pashto |
pt |
Portuguese |
ro |
Romanian |
ru |
Russian |
ru-Latn |
Russian (Latin) |
sd |
Sindhi |
si |
Sinhala |
sk |
Slovak |
sl |
Slovenian |
sm |
Samoan |
sn |
Shona |
so |
Somali |
sq |
Albanian |
sr |
Serbian |
st |
Southern Sotho |
su |
Sundanese |
sv |
Swedish |
sw |
Swahili |
ta |
Tamil |
te |
Telugu |
tg |
Tajik |
th |
Thai |
tr |
Turkish |
uk |
Ukrainian |
und |
Unknown language |
ur |
Urdu |
uz |
Uzbek |
vi |
Vietnamese |
xh |
Xhosa |
yi |
Yiddish |
yo |
Yoruba |
zh |
Chinese |
zh-Latn |
Chinese (Latin) |
zu |
Zulu |
Using mC4 Dataset with Hugging Face Datasets Library#
You can load the mC4 subset of any language like this:
from datasets import load_dataset
en_mc4 = load_dataset("mc4", "en")
And if you want to specify a list of languages:
from datasets import load_dataset
mc4_subset_with_five_languages = load_dataset("mc4", languages=["en", "fr", "es", "de", "zh"])
mC4 Dataset and Perplexity Sampling#
by De la Rosa et al. [2022]
The mC4 dataset, derived from web-crawled data, presents a massive amount of multilingual text, making training language models in constrained environments challenging. To address this issue, we explore sampling methods for creating subsets of the mC4 dataset that enable the training of language models with a reduced data size while maintaining adequate training effectiveness.
A technique called perplexity sampling is employed to construct these subsets. Originating from the construction of CCNet and their high-quality monolingual datasets from web-crawled data, perplexity sampling leverages fast language models trained on high-quality data sources, such as Wikipedia, to filter out texts that deviate significantly from the correct expressions of a language.
Perplexity is calculated for each document in a random subset of the mC4 dataset, extracting their distribution and quartiles. Two functions are then created to oversample the central quarters of the perplexity distribution, aiming to bias against documents with either too small or too large perplexity values. These functions are compared to random sampling to evaluate their effectiveness.
The first function, called the Stepwise function, oversamples the central quarters while subsampling the rest of the distribution. The second function uses a Gaussian-like distribution to weight the perplexity values, smoothing out the sharp boundaries of the Stepwise function and providing a better approximation to the desired underlying distribution.
Parameters of both functions are adjusted to extract a reduced-size subset of documents from the original mC4 dataset, significantly decreasing the raw data size. To ensure proper validation, a separate set of documents is extracted from the training dataset at each evaluation step, excluding those documents from training to avoid validating on previously seen data.
An analysis using t-SNE plots reveals that the distribution is uniform across different topics and clusters of documents. This is crucial because introducing a perplexity-based sampling method could potentially introduce undesired biases if perplexity correlates with some other aspect of the data, such as length. Overall, the perplexity sampling approach allows for the efficient use of resources in training language models without compromising the quality and representation of the dataset.
mC4 Sampling#
The mC4 dataset and perplexity sampling can be used to pretrain language models or word representations for various natural language processing tasks. By leveraging these techniques, you can reduce the amount of data required for training, making it more efficient and resource-friendly.
Perplexity Sampling#
To use perplexity sampling for creating subsets of the mC4 dataset, you can refer to the examples provided in the Dataset Summary section for each of the three sampling methods: Random, Gaussian, and Stepwise.
For instance, to use the Gaussian sampling method, you would need to install the KenLM library, download the Kneser-Ney language model for your desired language, and then use the following code:
from datasets import load_dataset
mc4gaussian = load_dataset(
"bertin-project/mc4-sampling",
"es",
split="train",
streaming=True,
sampling_method="gaussian",
perplexity_model="./es.arpa.bin",
boundaries=[536394.99320948, 662247.50212365, 919250.87225178],
factor=0.78,
width=9/2,
)
for sample in mc4gaussian:
print(sample)
break
Remember to replace the language code, perplexity model path, and boundaries specific to your language.
By utilizing the mC4 dataset and perplexity sampling techniques, you can effectively train language models on a reduced dataset size while maintaining the quality and representation of the data. This approach allows you to make the most of available resources without compromising the performance of your models.