Lexicon-Based Methods#
Lexicon-based methods are a popular approach to sentiment analysis. By leveraging predefined lists of positive and negative words, these methods can provide a simple yet effective way to assess the sentiment of textual data. However, the choice of lexicon, potential biases, and disagreements among lexicons can impact the performance of these methods. To address these challenges, it is crucial to select or create a lexicon that is well-suited for the specific domain and task at hand. Additionally, combining lexicon-based methods with other approaches, such as machine learning algorithms, can help improve the overall accuracy and robustness of sentiment analysis.
Lexicon-based methods in sentiment analysis rely on predefined lists of positive and negative words. These methods use sentiment lexicons or dictionaries that assign sentiment scores or polarities to words. There are two main types of lexicons: corpus-specific and general dictionaries.
Corpus-Specific Lexicons#
Corpus-specific lexicons are built for a specific domain. For instance, a lexicon for law-related documents might measure the number of times a judge uses the word “guilty” in a document. Similarly, a lexicon for movie reviews could count the number of times a reviewer uses the word “good” in a document.
Example 1: Measuring Economic Policy Uncertainty (EPU)
EPU lexicons are created to analyze news articles and gauge economic policy uncertainty. These lexicons consist of terms related to the economy, policy, and uncertainty, which are used to calculate an uncertainty score.

Fig. 58 US News-based economic policy uncertainty index#
US index: 10 major papers get monthly counts of articles with:
E{economic or economy}, andP{regulation or deficit or federal reserve or congress or legislation or white house}, andU{uncertain or uncertainty}
Divide the count for each month by the count of all articles
Normalize and sum 10 papers to get the U.S monthly index
Example 2: Monetary Policy Stance
Monetary policy lexicons are developed to assess central bank communications, such as meeting minutes or speeches. These lexicons contain words related to interest rates, inflation, and monetary policy actions to determine the stance of the central bank.
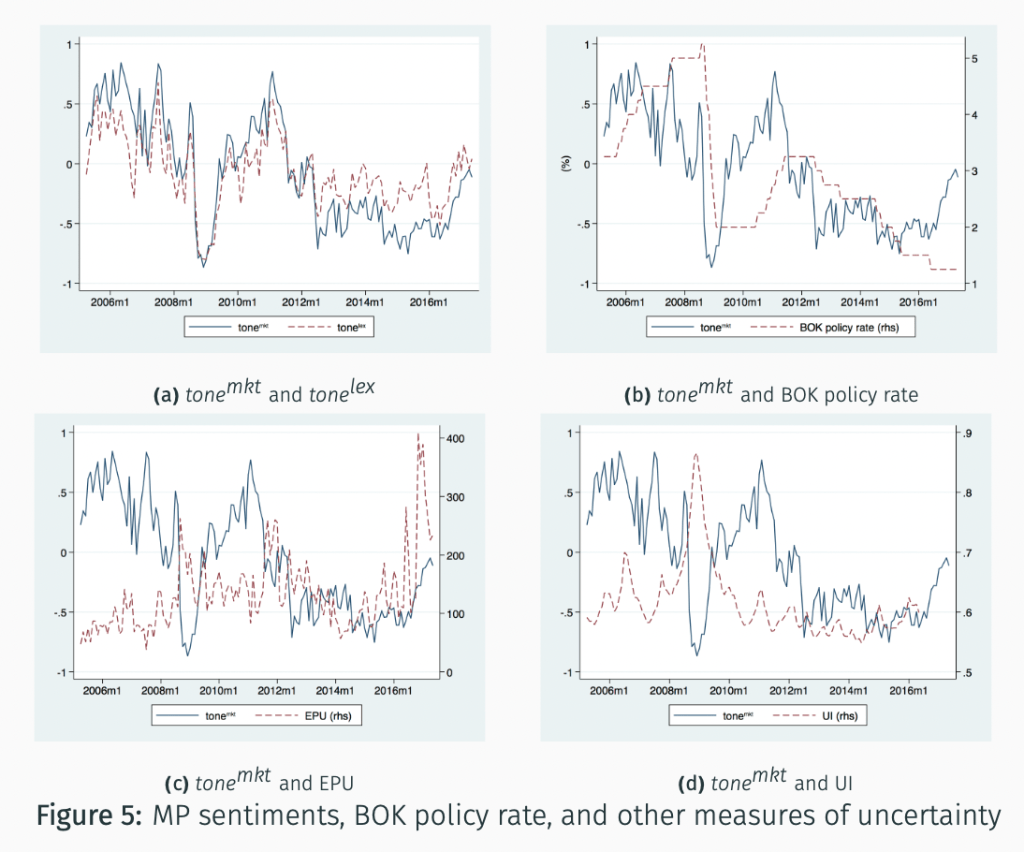
Fig. 59 BOK Monetary Policy Tone#
General Dictionaries#
General dictionaries are built for a more general domain and can be applied to various types of texts. Some popular general dictionaries include:
WordNet#
WordNet is a large lexical database of English words, created and maintained by Princeton University. It serves as a general-purpose dictionary and thesaurus, and it is widely used in natural language processing and computational linguistics tasks. The core of WordNet is its organization of words into sets of synonyms called synsets. Each synset represents a distinct concept or meaning, which allows for precise disambiguation of word senses in various contexts.
WordNet is a valuable resource for natural language processing tasks, particularly in tasks that require a deep understanding of word meanings and relationships. By utilizing its rich organization of synsets and lexical relations, WordNet can significantly improve the accuracy and effectiveness of sentiment analysis and other NLP algorithms.
Synsets and Relations#
In WordNet, words are grouped into synsets based on their meanings, and these synsets are interlinked through various lexical and conceptual-semantic relations. Some of the most common relations include:
Antonym: A word that expresses the opposite meaning of another word. For example, “hot” is an antonym of “cold.”
Holonym: A word that denotes a whole, of which the other word is a part. For example, “vehicle” is a holonym of “car.”
Meronym: A word that denotes a part, of which the other word is a whole. For example, “wheel” is a meronym of “car.”
Hypernym: A word that represents a more general concept than the other word. For example, “animal” is a hypernym of “dog.”
Hyponym: A word that represents a more specific concept than the other word. For example, “poodle” is a hyponym of “dog.”
These relations help to capture the hierarchical structure and semantic relationships between words, allowing for more accurate processing and understanding of natural language.
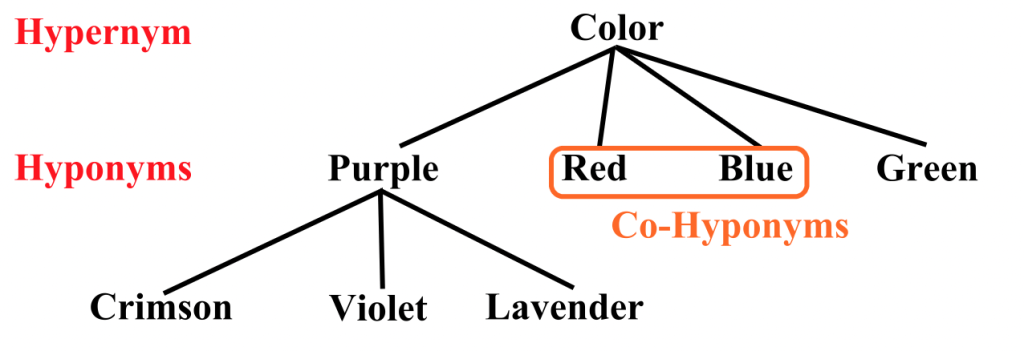
Fig. 60 WordNet Hierarchy Example#
WordNet Supersenses#
WordNet also organizes words into broader categories called supersenses. These categories provide a high-level classification of words based on their general meaning, making it easier to understand and analyze large sets of words.
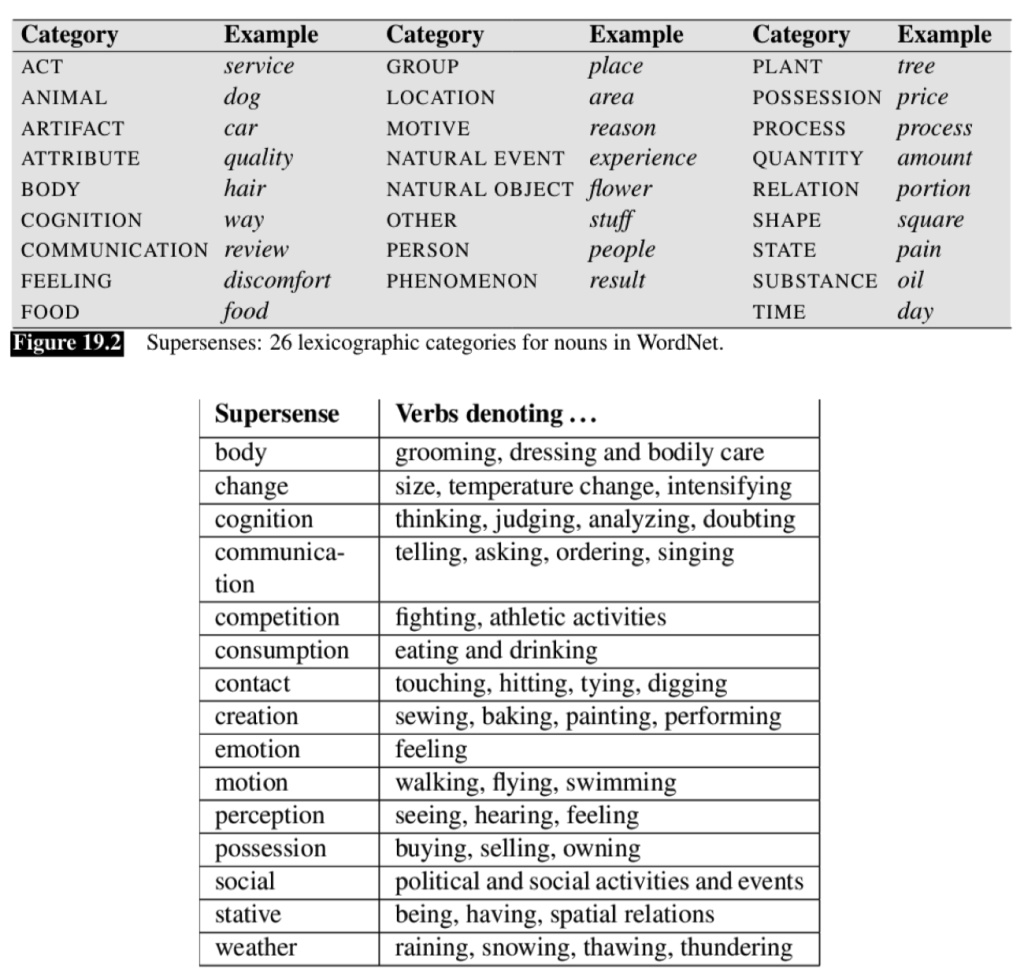
Fig. 61 WordNet Supersenses#
WordNet in NLP and Sentiment Analysis#
In natural language processing tasks, WordNet is often used for word sense disambiguation, sentiment analysis, text classification, and other tasks that require a deep understanding of word meanings and relationships. In the context of sentiment analysis, WordNet can be used to identify the polarity of words by analyzing their synonyms, antonyms, and related words.
For example, consider the word “bass.” In WordNet, “bass” has multiple synsets, representing its different meanings and senses:

Fig. 62 Bass Synsets#
Using WordNet, a sentiment analysis algorithm can determine the appropriate sense of “bass” in a given context and accurately identify its sentiment polarity.
MPQA Subjectivity Lexicon#
A lexicon that assigns words with subjectivity scores, indicating their polarity (positive, negative, or neutral) and intensity (strong or weak).
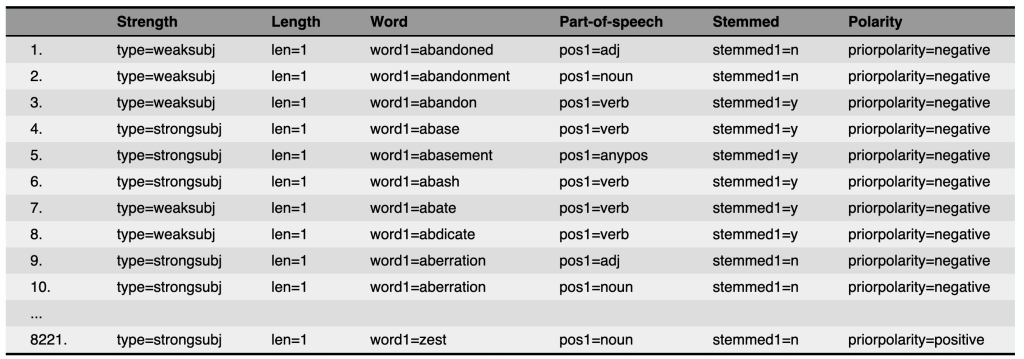
Fig. 63 MPQA Subjectivity Lexicon#
SentiWordNet#
A sentiment lexicon based on WordNet, which assigns positive, negative, and neutral sentiment scores to synsets.
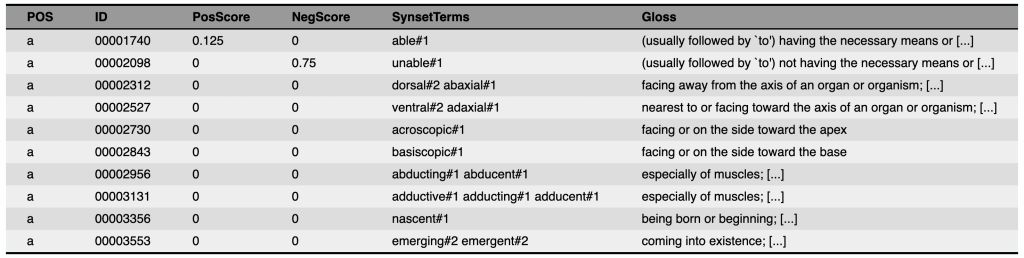
Fig. 64 SentiWordNet#
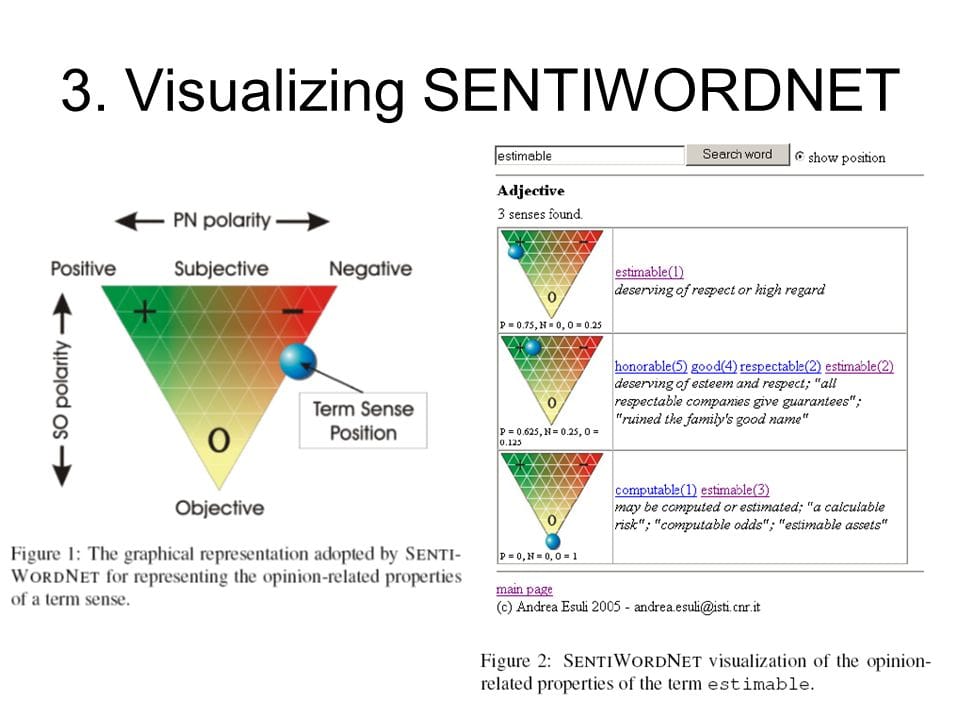
Fig. 65 Visualizing SentiWordNet#
Harvard General Inquirer#
A lexicon that categorizes words into various semantic categories, including positive and negative sentiment.
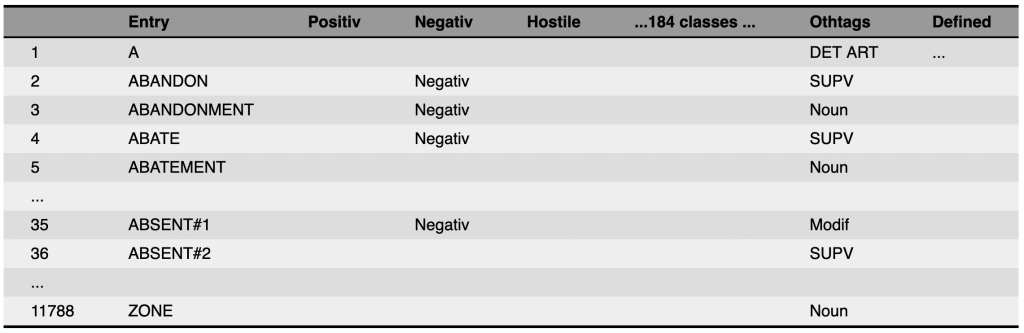
Fig. 66 Harvard General Inquirer#
LIWC: Linguistic Inquiry and Word Count#
A lexicon that categorizes words into various psychological constructs, including affective and cognitive processes.
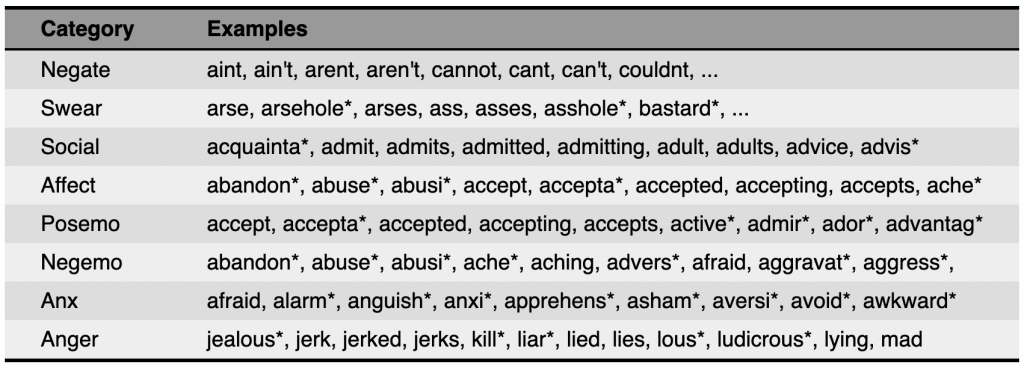
Fig. 67 LIWC#
Disagreement among Lexicons#
Different lexicons might assign different sentiment scores or polarities to the same word. This disagreement can arise due to differences in the construction methods, domain specificity, or subjective judgments made by the creators of the lexicons.

Fig. 68 Disagreement among Lexicons#
Sentiment Ambiguity and Context#
One limitation of lexicon-based methods is that they often fail to capture the context in which words appear. Sentiment can be ambiguous, and the meaning of a word can change depending on the surrounding words or the overall context of the text.
Example:
“I am not happy with the product.” vs. “I am happy with the product.”
In the first sentence, the negation “not” reverses the sentiment of the word “happy.” However, lexicon-based methods might not be able to account for this negation, leading to an incorrect sentiment assessment.
Handling Negations and Modifiers#
To address the issue of sentiment ambiguity and context, it is essential to consider linguistic constructs such as negations and modifiers. Negations can reverse the sentiment polarity of a word, while modifiers can either intensify or weaken the sentiment.
Example of a modifier:
“The movie was good.” vs. “The movie was incredibly good.”
In the second sentence, the modifier “incredibly” intensifies the sentiment of the word “good.”
To handle negations and modifiers in lexicon-based methods, you can employ rules or heuristics to adjust sentiment scores based on the presence of these constructs.
Incorporating Syntax and Semantics#
Another way to improve lexicon-based methods is to incorporate syntactic and semantic information from the text. By analyzing the grammatical structure and the relationships between words, you can better capture the sentiment of a text.
For example, dependency parsing can help identify negations, modifiers, and their respective targets, allowing you to adjust the sentiment scores accordingly.
Combining Lexicon-Based Methods with Machine Learning#
Lexicon-based methods can be combined with machine learning algorithms, such as Naive Bayes, Support Vector Machines, or Deep Learning models, to improve sentiment analysis performance. Machine learning algorithms can learn from labeled data and capture complex patterns in the text that are difficult to model using lexicons alone.
By using features derived from lexicon-based methods (e.g., sentiment scores, presence of positive/negative words) as input to machine learning models, you can create a more robust and accurate sentiment analysis system.
Bias in Lexicons#
Lexicons can contain biases that may affect the results of sentiment analysis. These biases can stem from cultural, political, or social factors that influence the way words are perceived and used.

Fig. 69 Bias in Lexicons#
NLP “Bias” is statistical bias#
In the context of NLP, the term “bias” often refers to statistical bias, which occurs when a model systematically misrepresents the true underlying sentiment of the data. This can happen when a lexicon-based method is unable to capture the nuances of language or relies too heavily on the presence of specific words.
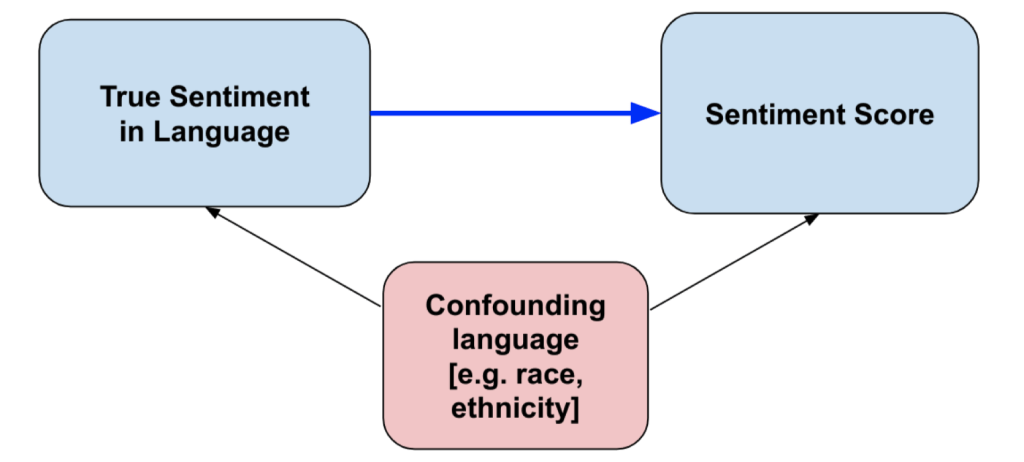
Fig. 70 NLP “Bias” is statistical bias#
Building Your Own Lexicons#
In some cases, it may be necessary to build a custom lexicon tailored to the specific domain or task. This can be achieved by:
Collecting a set of domain-specific texts (e.g., movie reviews, financial news articles, or social media posts).
Annotating the texts with sentiment labels (positive, negative, or neutral).
Identifying the most frequent and discriminative words for each sentiment category.
Assigning sentiment scores or polarities to the selected words based on their association with the sentiment categories.