Transformers#
On Transformers, TimeSformers, And Attention

Transformers are a highly influential and powerful class of Deep Learning models that have become a standard in numerous Natural Language Processing (NLP) tasks, and are on the verge of revolutionizing the field of Computer Vision as well.
In 2017, researchers from Google Brain published a groundbreaking paper titled “Attention Is All You Need” [Vaswani et al., 2017]. This paper introduced the Transformer model, which has since become a major force in the field of deep learning, particularly for NLP tasks.
The Transformer model is built upon the concept of attention, a mechanism that allows the model to focus on specific parts of the input data. Attention enables the model to weigh the importance of different input elements, thereby allowing it to concentrate on the most relevant aspects when processing data. This ability to focus on the most pertinent information has proven to be particularly effective for tasks that involve understanding and manipulating sequences of data, such as text or time-series information.
The Transformer model has demonstrated impressive performance across a wide range of NLP tasks. Some notable examples include machine translation, where the model converts text from one language to another; text summarization, which involves generating a concise summary of a longer text; and question answering, where the model provides answers to questions based on a given context.
Aside from its exceptional performance in NLP, the Transformer model has also shown great promise in other domains, such as image classification and speech recognition. In these tasks, the attention mechanism helps the model focus on the most significant features of the input data, which leads to better overall performance. As the model continues to be refined and adapted for different applications, it is poised to have a substantial impact on a wide range of fields, from NLP and computer vision to speech processing and beyond.
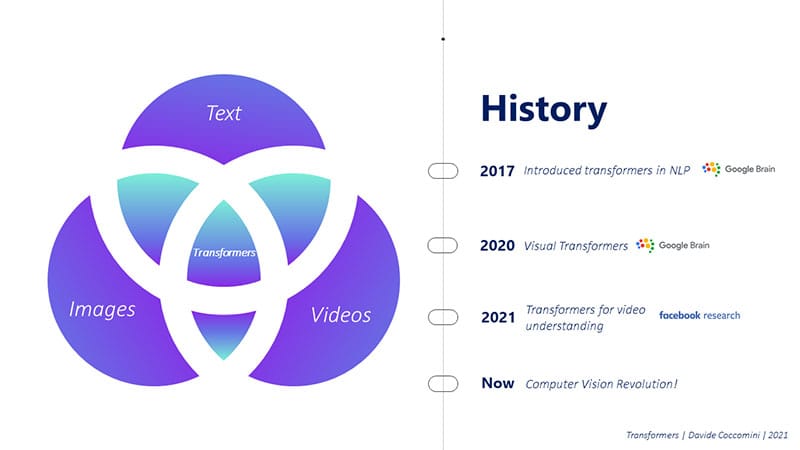
Fig. 98 History of Transformers#
In 2020, Google Brain posed an intriguing question: “Will Transformers be as effective on images as they are on text?” To explore this, a team of researchers published a paper titled “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” [Dosovitskiy et al., 2020]. This paper demonstrated the potential of Transformer models to excel in various Computer Vision tasks, including image classification and object detection.
The authors of the paper proposed a new Transformer-based architecture, called Vision Transformer (ViT), which treats image patches as if they were words in a text. By dividing an image into fixed-size, non-overlapping patches, and then flattening and linearly embedding them into a sequence of tokens, the model can apply the powerful attention mechanisms of Transformers to image data. The ViT model has shown impressive results on a variety of Computer Vision tasks, proving that the Transformer architecture can be highly effective for image processing as well as text-based tasks.
At the beginning of 2021, Facebook researchers took the concept of Transformers even further by introducing TimeSformer, a new variation of the Transformer model specifically designed for video understanding. They published a paper titled “Is space-time attention all you need for video understanding?” [Bertasius et al., 2021]. TimeSformer leverages the attention mechanism to process not only spatial information in video frames but also temporal information across multiple frames. This approach allows the model to recognize and analyze patterns in both space and time, making it well-suited for tasks such as action recognition and video classification.
These advancements in Transformer-based models for both image and video processing showcase the versatility of the Transformer architecture. By adapting the attention mechanism to different types of data, researchers are discovering new ways to leverage the power of Transformers across a wide range of domains.
Why do we need transformers?#
Transformers were introduced to address several limitations and challenges associated with previous models, particularly those based on Recurrent Neural Networks (RNNs). RNNs were designed to process sequences of data, such as text or audio, by maintaining an internal state that can capture information about previous elements in the sequence. However, there were a number of issues with RNNs that motivated the development of the Transformer architecture.
One of the main drawbacks of RNNs is their inherently sequential nature. In order to process an input sequence, RNNs must process each element one at a time, starting with the first and continuing through to the last. This sequential operation makes it challenging to parallelize RNN models, which in turn limits their computational efficiency and scalability. In contrast, Transformers can process all elements of a sequence simultaneously, enabling them to take full advantage of parallel computing resources and significantly improve training and inference times.
Another issue with RNNs is the difficulty they face in capturing long-range dependencies between distant elements within a sequence. Due to their sequential processing, RNNs can suffer from problems like gradient explosion or vanishing gradients, which make it challenging for them to learn and maintain information about relationships between far-apart elements. Transformers, on the other hand, leverage the attention mechanism to directly model relationships between all elements in the input, regardless of their positions in the sequence. This allows Transformers to better capture long-range dependencies and improves their overall performance in tasks that require understanding complex relationships within the data.
To illustrate the difference between RNNs and Transformers, consider the task of translating a sentence from English to Italian. With an RNN-based approach, the first word of the source sentence would be passed into an encoder along with an initial state. The resulting state would then be passed to a second encoder, together with the second word of the sentence, and so on, until the last word. The final state from the last encoder would then be fed into a decoder, which would generate the first translated word and a subsequent state. This state would be passed to another decoder, and the process would continue until the entire sentence was translated. This sequential approach is inherently slower and less efficient than the parallel processing enabled by Transformer models, which can consider the entire input sequence at once and generate translations more effectively.

Fig. 99 Problem with RNNs#
Attention is all you need?#

Fig. 100 Attention#
The attention mechanism is a key component of the Transformer architecture that allows it to extract relevant information from a sentence or sequence in a parallelized manner, as opposed to the sequential processing of traditional Recurrent Neural Networks (RNNs). The attention mechanism enables the model to selectively focus on different parts of the input data that are most relevant to the task at hand, and it can do so simultaneously for all elements in the sequence.
Consider the example sentence: I gave my dog Charlie some food.
In this context, let’s explore how the attention mechanism can identify important relationships between words in the sentence to better understand its meaning.
Focusing on the word “gave”, we may want to determine which words in the sentence provide context to the action of giving. In this case, we could ask, “Who gave the food to the dog?” The attention mechanism would recognize the importance of the word “I” in answering this question, as it indicates the subject performing the action.
Similarly, we might want to determine the recipient of the action. By asking, “To whom did I give the food?”, the attention mechanism would identify the words “dog” and “Charlie” as crucial for understanding the recipient of the action.
Finally, to determine the object of the action, we could ask, “What did I give to the dog?” Here, the attention mechanism would focus on the word “food”, as it represents the object being given.
In each of these cases, the attention mechanism can identify and focus on the most relevant words in the sentence to provide context and meaning to the central action of “gave”. By doing so, the model can extract essential information and relationships within the sentence in a highly parallelized and efficient manner. This powerful mechanism is at the core of the Transformer architecture, enabling it to excel in various natural language processing tasks, such as machine translation, text summarization, and question answering.
How do we implement this attention mechanism?#

Fig. 101 Attention mechanism#
To understand and implement the attention mechanism, let’s break it down into a series of steps. We’ll use an analogy with databases to help explain the process more clearly.
Encoding words as vectors: First, we represent the sentence as a set of vectors. Each word in the sentence is encoded into a vector using a word embedding mechanism. We’ll call these vectors “keys” (K).
Defining the query: We then define a query (Q) as a vector representing the word we want to focus on. The query can be a word from the same sentence (self-attention) or a word from another sentence (cross-attention).
Computing similarity: We calculate the similarity between the query (Q) and each of the keys (K) in the sentence. This is typically done by computing the dot product between the query vector and the transpose of the key vectors. The result is a vector of scores, with each score representing the similarity between the query and a key.
Normalization: We normalize the scores by applying the softmax function, which converts the scores into a probability distribution. The resulting vector contains the “attention weights” that signify the importance of each word in the sentence with respect to the query.
Computing the context: We multiply the attention weights by the sentence vectors, which are the same dimension as the keys (K). This results in a context vector ©, which is a weighted sum of the words in the sentence, capturing the relevant context for the word we want to focus on.
Linear transformation: Finally, the context vector © is passed through a linear layer, which is a fully connected layer, to obtain the final output of the attention mechanism.
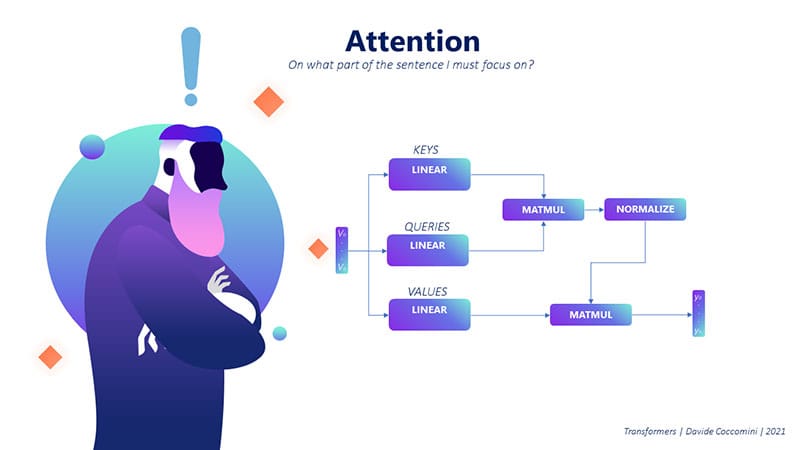
Fig. 102 Attention implementation#
To summarize, the attention mechanism involves encoding words in a sentence as vectors, defining a query vector for the word of interest, calculating the similarity between the query and each word in the sentence, and using the resulting attention weights to compute a context vector that captures the relevant information about the word of focus. This context vector is then transformed by a linear layer to obtain the final output.
By following these steps, the attention mechanism can selectively focus on different parts of the input sentence to provide the necessary context for understanding and processing the information. This powerful mechanism is at the core of the Transformer architecture and plays a crucial role in its success in various natural language processing tasks.
Multi-head attention#
The basic attention mechanism described earlier focuses on a single word and its context within a sentence. However, to effectively capture various relationships between words, we need to examine the input from multiple perspectives. This is where the multi-head attention mechanism comes into play.
Multi-head attention is an extension of the basic attention mechanism that utilizes multiple sets of queries, keys, and values, known as “heads”. Each head has its own set of learnable parameters and is designed to capture different aspects of the relationships between words in the input. By using multiple heads, the model can attend to different parts of the input simultaneously and understand the input more comprehensively.
Here’s how multi-head attention works:
Multiple sets of queries, keys, and values: Instead of using a single set of query, key, and value vectors, we use multiple sets (or “heads”) with their own learnable parameters. Each head focuses on different aspects of the relationships between words in the input.
Compute attention for each head: For each head, we perform the same attention mechanism steps as before, namely, computing similarity scores, normalizing the scores using the softmax function, computing the context vector, and transforming the context vector using a linear layer.
Concatenate the results: Once we have obtained the context vectors for each head, we concatenate these vectors to form a single, combined context vector. This concatenated vector captures information from all the attention heads and provides a more comprehensive understanding of the relationships between words in the input.
Final linear transformation: The concatenated vector is passed through an additional linear layer to produce the final output of the multi-head attention mechanism.
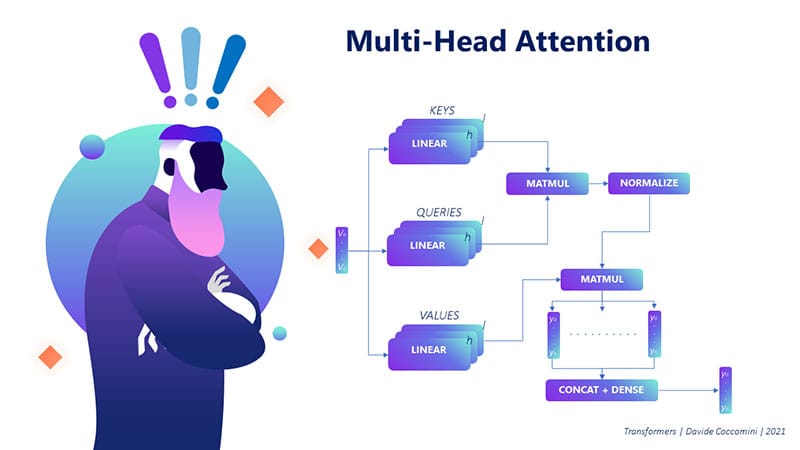
Fig. 103 Multi-head attention#
In summary, multi-head attention enhances the basic attention mechanism by using multiple heads to focus on different parts of the input simultaneously. This allows the model to capture a more comprehensive understanding of the relationships between words in the input, ultimately improving its performance in various natural language processing tasks.
Tranformer Architecture#
The Transformer architecture, designed for various natural language processing tasks such as translation, consists of two primary components: the encoder and the decoder. Let’s consider a Transformer model trained to translate a sentence from English to Italian and examine the roles of the encoder and decoder in this process.

Fig. 104 Transformer architecture#
Encoder#
The encoder’s role is to convert the input sentence into a meaningful vector representation. The steps involved are as follows:
Tokenization: The input sentence in English is first tokenized into individual words.
Word Embedding: Each word is converted into a vector using a word embedding mechanism.
Positional Encoding: Since the Transformer does not process the sentence sequentially, positional encoding vectors are added to the word embeddings to retain information about the order of the words in the sentence. These vectors are computed using sine and cosine functions and are of the same size as the word embedding vectors.
Multi-head Attention: The combined vectors are passed through the multi-head attention mechanism, which captures the relationships between words in the input sentence.
Normalization and Feed-Forward Neural Network: The output from the attention mechanism is normalized and passed through a feed-forward neural network.
Stacking Encoder Layers: The encoding process can be repeated multiple times, with each layer refining the sentence representation further.
Decoder#
The decoder’s responsibility is to transform the encoded vector representation into a translated sentence in the target language, in this case, Italian. The steps involved are:
Input Preparation: The decoder takes as input the previously translated words in Italian and the output from the encoder. Initially, the input consists of the first two translated words.
Positional Encoding and Multi-head Attention: The decoder applies positional encoding and multi-head attention mechanisms to the translated words in Italian.
Concatenation and Recalculation: The output from the attention mechanism is concatenated with the output from the encoder, and attention is recalculated on the concatenated vector.
Normalization and Feed-Forward Neural Network: The concatenated vector is normalized and passed through a feed-forward neural network.
Predicting Next Word: The output from the neural network is a vector of potential candidates for the next word in the translated Italian sentence.
Iterative Decoding: In the next iteration, the decoder takes as input the first three translated words in Italian along with the encoder’s output. This process is repeated until the entire translated sentence is generated.
In summary, the Transformer architecture consists of an encoder that converts the input sentence into a vector representation and a decoder that translates the encoded vector into the target language. The model leverages multi-head attention, positional encoding, and feed-forward neural networks to capture and process the relationships between words effectively, resulting in improved performance in various natural language processing tasks.

Fig. 105 Problems with the Transformer architecture#
Problems with the Transformer architecture#
The Transformer architecture has revolutionized the field of natural language processing, offering significant improvements in various tasks. However, it also comes with some inherent limitations:

Fig. 106 Problems with the Transformer architecture#
Computational Complexity: One of the main strengths of the Transformer architecture, its attention mechanism, also contributes to its primary weakness: high computational complexity. The attention mechanism requires a significant amount of computation, particularly when dealing with long input sequences.
Quadratic Scaling: In order to compute the attention for each word with respect to all other words, the model needs to perform \(N^2\) calculations, where N is the number of words in the input. This can be visualized as filling a matrix with attention values for each word pair, leading to quadratic scaling in terms of computational complexity.
Masked Attention: To mitigate the computational complexity to some extent, particularly in the decoder, masked attention is sometimes used. Masked attention is a mechanism that calculates the attention of a word only with respect to previous words, excluding the following words in the sequence. While this approach reduces complexity, it still doesn’t fully resolve the issue, especially for very long sequences.

Fig. 107 Attention matrix#
In summary, while the Transformer architecture has significantly advanced the field of natural language processing, it comes with some inherent challenges, particularly in terms of computational complexity and quadratic scaling. Efforts to address these issues are ongoing, with researchers continually exploring new techniques and optimizations to further improve the efficiency and performance of Transformer-based models.
Attention Is Not All You Need#
In March 2021, Google researchers published a paper titled “Attention Is Not All You Need” [Dong et al., 2021], challenging the prevailing notion that the self-attention mechanism was the sole key to the Transformer’s success.
In the paper, the researchers conducted experiments specifically analyzing the behavior of the self-attention mechanism in isolation, without incorporating any of the other components that make up the Transformer architecture. They sought to understand the self-attention mechanism’s limitations and how it interacts with the other components of the Transformer model.
Their findings revealed that, when used in isolation, the self-attention mechanism converges to a rank 1 matrix with a doubly exponential rate. In other words, the self-attention mechanism alone is not sufficient to achieve meaningful results, and it is practically ineffective without the other components of the Transformer architecture.
The research underscores the importance of considering the interplay of various components within the Transformer model, rather than solely focusing on the attention mechanism. This insight can help guide further development and improvement of Transformer-based models, as researchers continue to explore the optimal balance and combination of different components for various natural language processing tasks.
Note
In the context of the paper “Attention Is Not All You Need,” “convergence to a rank 1 matrix” refers to the behavior of the self-attention mechanism when used in isolation. A rank 1 matrix is a matrix whose columns (or rows) can be expressed as a linear combination of a single vector. In other words, all the columns (or rows) of the matrix are essentially scaled versions of the same vector.
Converging to a rank 1 matrix implies that the self-attention mechanism, when used alone, produces an output that has very limited expressiveness and diversity. Since the information in a rank 1 matrix can be represented by just one vector, it indicates that the self-attention mechanism isn’t capable of capturing complex relationships and patterns in the data by itself.
The researchers found that combining the self-attention mechanism with other components of the Transformer architecture, like skip connections and MLPs, is essential to achieving the powerful performance that the Transformer model is known for. The combination of these components allows the Transformer to overcome the limitations of the self-attention mechanism and effectively capture complex patterns and dependencies in the input data.
So why are transformers so powerful?#
The success of the Transformer model is not solely due to the self-attention mechanism, as previously thought. The Google researchers discovered that the power of the Transformer model comes from a combination of components working together:
Self-attention mechanism: This component allows the model to focus on different parts of the input, depending on their relevance to the task at hand.
Skip connections: Also known as residual connections, skip connections allow the model to maintain information from earlier layers without losing it in the process. This helps the model diversify the distribution of paths and avoid convergence to a rank 1 matrix, which would make it ineffective.
MLP (Multilayer Perceptron): The MLP component adds non-linearity to the model due to the activation functions used in its layers. This non-linearity helps increase the rank of the matrix, contributing to the model’s expressive power.
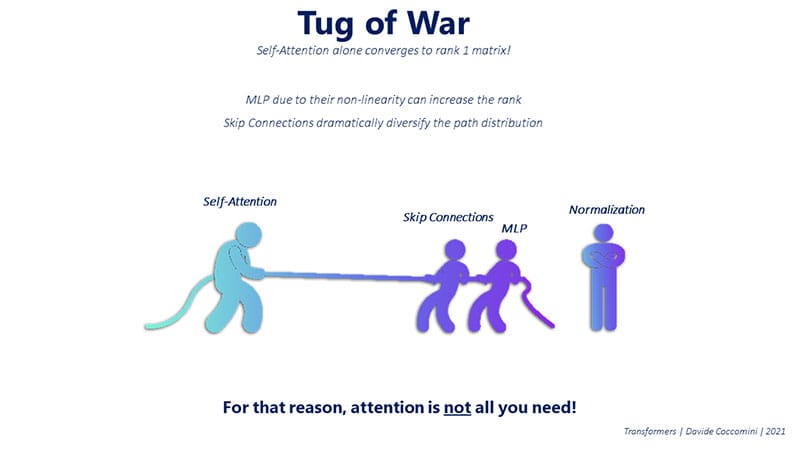
Fig. 108 Tug of war between the self-attention mechanism and skip connections and MLP#
In summary, the true strength of the Transformer model comes from the combined effect of the self-attention mechanism, skip connections, and MLP. These components work together in a delicate balance to make the Transformer architecture highly effective at processing and understanding complex input data, ultimately leading to its impressive performance in various natural language processing tasks.
Vision Transformers#
The success of Transformers in the field of Natural Language Processing raises the question of whether they can be equally effective in the realm of image processing. In order to explore this possibility, let’s consider an example: a picture of a dog standing in front of a wall.
When we look at the picture, our attention is naturally drawn to the dog, which is the main subject of the image, while the wall serves as the background. This ability to focus on the dominant subject in the scene is a crucial aspect of understanding and interpreting the image’s content.
This concept of focusing on the most important parts of the input is similar to what the self-attention mechanism does when applied to sentences in Natural Language Processing tasks. The self-attention mechanism helps the model pay attention to the most relevant words or phrases, depending on the context and the task.
Applying the self-attention mechanism to images involves the same principle. By focusing on the most important features or regions in the image, the model can effectively extract valuable information, recognize patterns, and understand the content of the image. This approach has led to the development of Vision Transformers, which leverage the power of the Transformer architecture to achieve impressive performance in various computer vision tasks.

Fig. 109 Vision Transformer#
How to input images into a transformer?#
Fig. 110 Vision Transformer with pixels#
Feeding images into a Transformer requires a method that efficiently handles the high computational complexity associated with image data. One might initially consider using all the image pixels as input to the Transformer, but this approach would not be efficient due to the significant computational resources required.
The attention calculation in Transformers has a complexity of \(O(N^2)\), where \(N\) represents the number of pixels. Consequently, the attention calculation would require \(O(N^4)\) operations, which is highly resource-intensive and not a practical solution for processing images, especially those with high resolutions.
A more feasible approach to input images into a Transformer is to divide the image into smaller patches and convert each patch into a vector. This method greatly reduces the computational complexity while still preserving the necessary information for the model to process.
By breaking the image down into smaller patches, the Transformer can focus on individual regions, extracting valuable features from each patch. Each patch is then converted into a vector using a linear projection, allowing the Transformer to process the image data more efficiently without compromising its ability to perform various computer vision tasks effectively.

Fig. 111 Linear projection of the patches#
Vision Transformer Architecture#
The Vision Transformer (ViT) architecture is designed to process images effectively by adapting the standard Transformer architecture for computer vision tasks. Here’s a breakdown of the key steps involved in the Vision Transformer architecture:
The image is divided into patches, and each patch is converted into a vector using a linear projection. These vectors represent the individual regions of the image, capturing essential information from each patch.
Positional encoding vectors are added to the patch vectors. This step is crucial for providing the Transformer with information about the spatial positions of the patches within the image, ensuring that the model can understand the relationships between different regions.
The combined patch and positional encoding vectors are then passed through a standard Transformer architecture, which is composed of layers of self-attention and feed-forward neural networks. This allows the model to process the image data effectively, learning to recognize patterns and features within the image.
The output of the Transformer is a vector that represents the entire image, encapsulating the critical information and relationships between the different regions. This vector is then passed to a classifier, which can be a linear layer, a convolutional neural network, or another appropriate model, to produce the final result. This could be a classification label, an object detection output, or any other desired output for a specific computer vision task.

Fig. 112 Vision Transformer Architecture#
The Vision Transformer architecture leverages the power of Transformers to tackle various computer vision tasks efficiently and effectively, achieving impressive results in image classification, object detection, and more.
Transformer in Transformer#

Fig. 113 Transformer in Transformer#
The Transformer in Transformer (TnT) architecture [Han et al., 2021] aims to address the issue of losing spatial information within image patches when transforming them into vectors for the standard Vision Transformer. The authors propose an approach that preserves the arrangement of pixels within patches, leading to improved performance on various computer vision tasks. Here’s a step-by-step explanation of the TnT architecture:
For each individual patch (pxp) of the input image, which consists of 3 RGB channels, the TnT architecture transforms it into a c-channel tensor. This tensor retains the spatial information and arrangement of pixels within the patch.
The c-channel tensor is then divided into smaller \(p^\prime\) parts, where \(p^\prime\) is less than \(p\). For example, if \(p^\prime\) is 4, the tensor is divided into four smaller sections.
By dividing the tensor into smaller parts, \(p^\prime\) vectors in \(c\) dimensions are obtained. These vectors now carry information about the arrangement of pixels within the patch, ensuring that important spatial details are preserved.
The \(p^\prime\) vectors are concatenated and linearly projected to match the size of the vector obtained from the linear projection of the original patch. This step allows the model to effectively combine the preserved spatial information with the original patch representation.
The concatenated and linearly projected vectors are then combined with the original patch vector, forming a more informative representation of the image patch for the Transformer to process.

Fig. 114 Transformer in Transformer Architecture#
The Transformer in Transformer architecture enhances the standard Vision Transformer by incorporating crucial spatial information from image patches. As a result, TnT delivers improved performance on a variety of computer vision tasks, such as image classification and object detection.
TimeSformers#
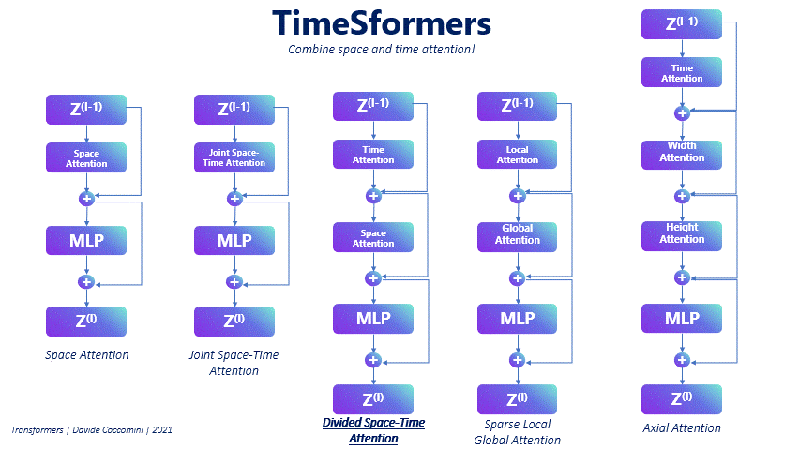
Fig. 115 TimeSformer Architecture#
n 2021, Facebook researchers explored the possibility of applying the Vision Transformer architecture to videos, leading to the development of TimeSformers. The core idea is to divide a video into individual frames and process them using a similar procedure as for images. However, there is an essential distinction between TimeSformers and Vision Transformers: TimeSformers must take into account the temporal dimension of the video in addition to the spatial dimension.
To address this challenge, the authors proposed several new attention mechanisms. These mechanisms range from focusing exclusively on space (used primarily as a reference point) to computing attention axially, scattered, or jointly between space and time.
The most effective method, achieving the best results, is called Divided Space-Time Attention. This approach involves selecting a frame at a specific time (t) and one of its patches as a query. The model then computes the spatial attention across the entire frame, followed by calculating the temporal attention within the same patch of the query but in the previous and next frames.
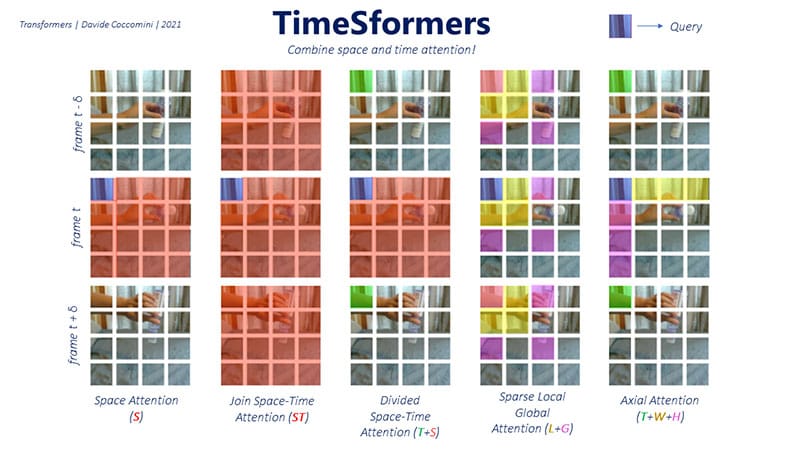
Fig. 116 TimeSformer Attention Mechanisms#
The Divided Space-Time Attention approach works exceptionally well because it learns more distinct features compared to other methods. This capability enables the model to better understand and classify videos from various categories. By incorporating both spatial and temporal dimensions, TimeSformers can effectively process and analyze video data, leading to improved performance on video-related tasks.
In the following visualization, each video is represented by a point in space, and its color indicates the category it belongs to.

Fig. 117 TimeSformer Divide Space-Time Attention#
The authors discovered that increasing the resolution of the video leads to better model accuracy, up to a certain point. Similarly, they found that as the number of frames in a video increases, the model’s accuracy also improves. However, they were unable to conduct tests with a higher number of frames than what is shown in the graph, so it remains unclear whether the accuracy could continue to improve with even more frames. The upper limit of this potential improvement is still unknown.
In summary, TimeSformers benefit from higher resolution and a greater number of frames in videos, which contribute to improved accuracy in understanding and classifying video content. However, further research is needed to determine the optimal balance between resolution and frame count for the best possible performance.
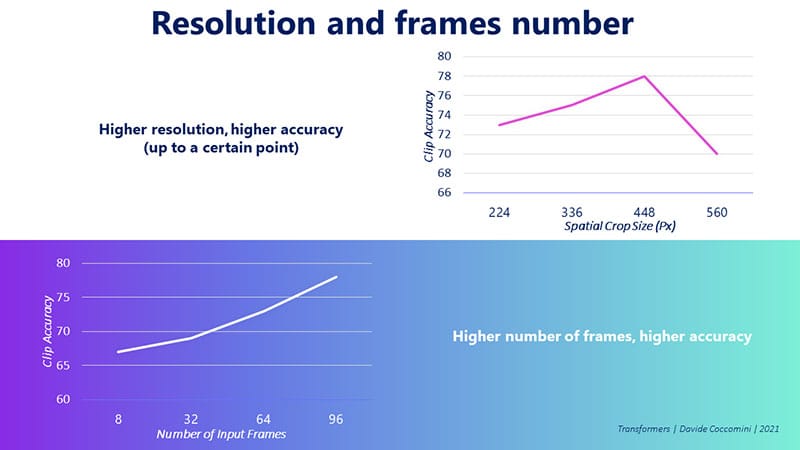
Fig. 118 TimeSformer Resolution#
Similar to Vision Transformers, the authors of TimeSformers explored the impact of using larger training datasets on the model’s accuracy. They found that as the number of training videos considered increases, the accuracy of the model also improves. This suggests that TimeSformers, like Vision Transformers, can benefit from larger datasets for better performance.
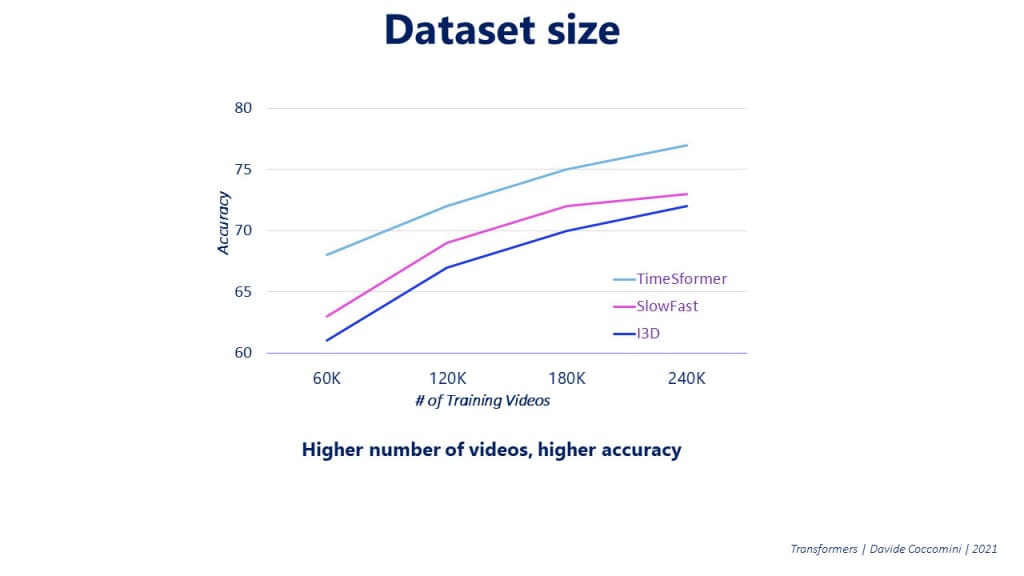
Fig. 119 TimeSformer Dataset#
In essence, having more training data allows the model to learn a broader range of features and patterns, which in turn helps it to generalize better when encountering new video content. This finding highlights the importance of using large and diverse training datasets to maximize the potential and accuracy of TimeSformers.
Conclusion#
Transformers have recently made their way into the realm of computer vision, showing great potential to either replace traditional convolutional networks or, at the very least, claim a significant role within this domain.
Originally, transformers gained prominence in the field of Natural Language Processing, where they demonstrated remarkable performance across a variety of tasks. This powerful architecture has since been adapted and applied to computer vision, yielding promising results that suggest their effectiveness will only continue to grow in the future.
The success of transformers in both NLP and computer vision showcases their versatility and adaptability, indicating that they may play an increasingly important role in the advancement of machine learning techniques across multiple domains.
Multimodal Machine Learning#
Multimodal machine learning is an emerging field that aims to develop models capable of processing and combining different types of data, much like how humans are able to draw inferences from various sources of information.
People can understand the world around them by integrating information gathered through their senses, such as sight, smell, hearing, and touch. This ability to process and synthesize multiple sources of data allows us to make sense of our surroundings.
The challenge in multimodal machine learning lies in designing models that can treat various inputs consistently and effectively without losing vital information. Transformers, with their proven capability to work with different data types, present a promising solution for this task.
As a versatile architecture, transformers can process and combine diverse data sources within a single model, paving the way for advancements in multimodal machine learning and the development of more sophisticated AI systems that can better understand and interact with the world around them.
VATT: Transformers for Multimodal Self-Supervised Learning#
VATT (Visual-Audio Text Transformer) is a significant development in the field of Multimodal Machine Learning [Akbari et al., 2021]. This innovative architecture utilizes a single Transformer Encoder to process different types of input data simultaneously, transforming each into a sequence of tokens.
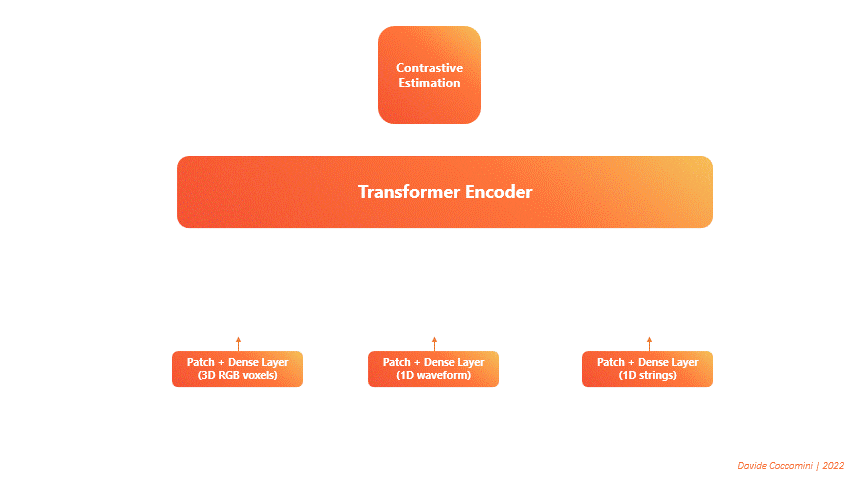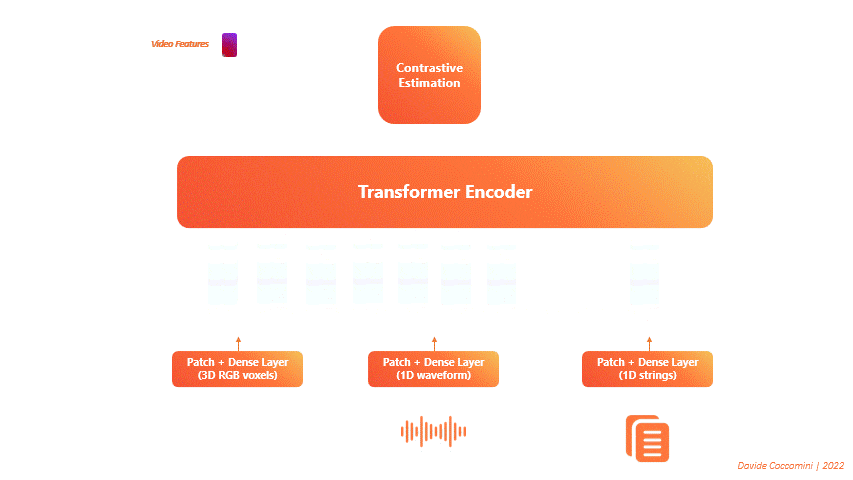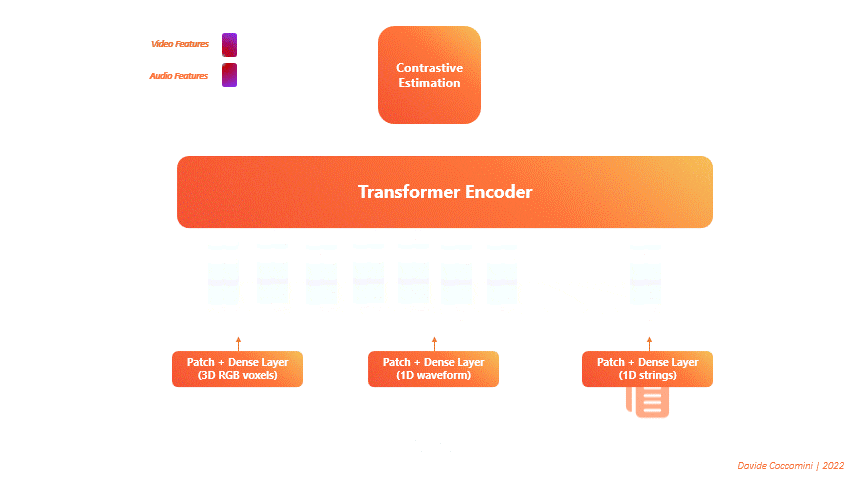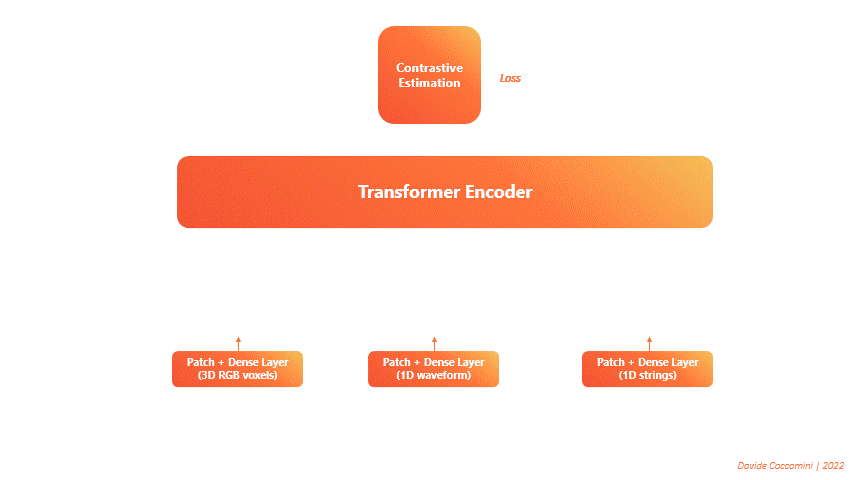
Fig. 120 VATT Architecture#
During the forward pass, the transformer takes in these sequences and generates three distinct sets of features, one for each type of input data. These features are then fed into a contrastive estimation block, which calculates a single loss and performs the backward pass. As a result, the model learns to minimize the loss by better managing and integrating information from all three data sources.
VATT embodies the primary goal of Multimodal Machine Learning, which is to develop a unified model capable of handling and processing various data types effectively. This breakthrough has the potential to significantly advance the field and inspire further innovations in the development of multimodal AI systems.
GATO: A Generalist Agent#
he concept of creating a neural network that can handle various input types and perform multiple tasks is the driving force behind GATO (Generalist Agent) [Reed et al., 2022]. As one of the most remarkable accomplishments in the field, GATO demonstrates the potential for multi-modal, multi-task, and multi-embodiment learning in a single model.
GATO operates using a single Transformer Encoder, which processes a sequence of tokens representing different data types. The key to GATO’s success lies in its ability to unify these inputs and leverage the Transformer architecture to learn how to effectively combine diverse data types. As a result, GATO can perform various tasks, achieving an unparalleled degree of generalization.
In summary, GATO represents a significant advancement in the development of neural networks capable of handling multiple input types and tasks, showcasing the potential for even more sophisticated AI systems in the future.
Next#

