Large Language Models#
What are Large Language Models?#
Large Language Models (LLMs) are a type of deep learning model specifically designed for natural language processing (NLP) tasks. These models are trained on vast amounts of text data to learn complex language patterns, structures, and semantic relationships. As a result, they are capable of understanding and generating human-like text, making them suitable for a wide range of applications, such as machine translation, text summarization, question-answering, sentiment analysis, and more.
Some key aspects of LLMs include:
Architecture: LLMs are typically based on architectures like the Transformer, which has become the foundation for many state-of-the-art NLP models. The Transformer architecture is characterized by its self-attention mechanism, which enables the model to capture long-range dependencies and relationships between words in a sentence.
Pre-training: LLMs are pre-trained on massive datasets using unsupervised learning techniques, such as masked language modeling or causal language modeling. This pre-training phase enables the models to learn general language representations, including grammar, syntax, and semantics, as well as factual and contextual knowledge.
Fine-tuning: After pre-training, LLMs can be fine-tuned on specific tasks or domains using smaller labeled datasets. This process allows the models to adapt their general language understanding to the nuances and requirements of a particular task, resulting in better performance.
Transfer learning: LLMs are capable of leveraging knowledge learned during pre-training to perform well on a wide range of NLP tasks with minimal fine-tuning. This ability to transfer knowledge across tasks and domains is a key advantage of LLMs, as it reduces the need for large labeled datasets for each specific task.
Examples of LLMs: Some well-known LLMs include GPT-3 (OpenAI), BERT (Google), RoBERTa (Facebook), and T5 (Google). These models have achieved state-of-the-art results on various NLP benchmarks, demonstrating their versatility and effectiveness.
LLMs have significantly advanced the field of NLP and have found numerous practical applications in areas such as chatbots, content generation, summarization, and sentiment analysis, among others. However, they also come with challenges, such as the need for vast computational resources during training, potential biases in the training data, and ethical concerns related to content generation.
Capabilities of LLMs#
Large Language Models (LLMs) have a wide range of capabilities that make them highly versatile and useful across many natural language processing (NLP) tasks. Some of the key capabilities of LLMs include:
Language understanding: LLMs are trained on vast amounts of text data, enabling them to learn and understand complex language patterns, structures, and semantic relationships. This understanding allows LLMs to effectively process and interpret text in various contexts, making them suitable for tasks such as sentiment analysis, named entity recognition, and relationship extraction.
Text generation: LLMs can generate coherent and contextually relevant text based on a given input, which makes them valuable for applications like content generation, text summarization, and paraphrasing. By fine-tuning LLMs on specific domains, it is possible to generate text that meets the requirements of various use cases, such as news articles, marketing copy, or creative writing.
Question answering: LLMs have the ability to understand and extract information from text, allowing them to provide answers to specific questions. This capability is useful for tasks like reading comprehension, fact-checking, and building conversational agents that can provide useful information or support to users.
Translation: LLMs can learn to translate text between different languages, making them effective tools for machine translation. By training LLMs on parallel corpora, they can learn to map between languages and generate translations that are both accurate and fluent.
Zero-shot and few-shot learning: LLMs can perform tasks without having seen any specific examples during training (zero-shot) or with only a few examples (few-shot). This capability enables LLMs to generalize across tasks and domains with minimal data, which is particularly useful when labeled data is scarce or expensive to obtain.
Text classification: LLMs can classify text into categories based on their content, sentiment, or other attributes. This capability is useful for tasks like sentiment analysis, topic classification, and spam detection.
Sequence-to-sequence tasks: LLMs can be used for sequence-to-sequence tasks, such as abstractive summarization, dialogue generation, and code generation. These tasks involve transforming input sequences into output sequences, often with different lengths and structures.
Text completion and prediction: LLMs can predict missing words or phrases in a given text, enabling applications like autocomplete, spell-checking, and grammar correction.
Text similarity and clustering: LLMs can be used to measure the similarity between texts or to group similar texts together, which is useful for applications like document retrieval, duplicate detection, and content recommendation.
These capabilities make LLMs highly versatile and applicable across a wide range of NLP tasks and domains. However, it is essential to carefully consider the limitations and potential biases of LLMs when using them in real-world applications.
Methodologies#
Large Language Models (LLMs) employ various methodologies during their development, encompassing architecture design, pre-training, fine-tuning, and transfer learning. These methodologies contribute to their ability to understand and generate human-like text effectively. Here, we outline the key methodologies employed by LLMs:
Architecture design: LLMs typically use advanced neural network architectures, such as the Transformer, which has become the foundation for many state-of-the-art NLP models. Transformer-based architectures are characterized by their self-attention mechanism, which allows models to capture long-range dependencies and relationships between words in a sentence. Some popular architectures include GPT, BERT, RoBERTa, and T5.
Pre-training: LLMs undergo a pre-training phase on massive datasets using unsupervised learning techniques. This process involves training the model to predict masked or missing words in a sentence, allowing it to learn language patterns, grammar, syntax, semantics, and even factual information from the data. Pre-training on large-scale datasets enables LLMs to acquire general language representations that can be fine-tuned for specific tasks later.
Fine-tuning: After pre-training, LLMs can be adapted to specific tasks or domains using smaller labeled datasets. Fine-tuning involves training the model on task-specific data to adjust its learned representations and make them more suitable for the target task. This process can significantly improve the model’s performance on tasks such as sentiment analysis, question-answering, or machine translation.
Transfer learning: LLMs can leverage the knowledge they acquired during pre-training to perform well on various NLP tasks with minimal fine-tuning. Transfer learning refers to the ability of a model to apply its learned representations from one task or domain to another, reducing the need for large labeled datasets for each specific task. This capability is a key advantage of LLMs and is a primary reason behind their widespread adoption in NLP.
Task-specific methodologies: Depending on the target task, LLMs may incorporate additional methodologies to enhance their performance. For instance, sequence-to-sequence models like T5 employ an encoder-decoder architecture for tasks such as summarization or translation. Similarly, BERT and RoBERTa use masked language modeling during pre-training to learn bidirectional context, making them suitable for tasks that require understanding the context from both sides of a word or phrase.
Prompt engineering: To effectively use LLMs for a given task, prompt engineering techniques are often employed. This involves designing and refining inputs (prompts) to obtain better, more accurate, and contextually relevant outputs. Crafting effective prompts can significantly influence the quality of the generated responses and improve the model’s reliability and usefulness across various applications.
These methodologies work in concert to enable LLMs to excel at diverse NLP tasks and adapt to new challenges with minimal data. However, the development and application of LLMs also raise concerns regarding computational resource requirements, potential biases, and ethical considerations that must be addressed for their responsible use.
Applications#
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. Their versatility has led to numerous practical applications in various domains. Some of the key applications of LLMs include:
Machine translation: LLMs have significantly improved the quality of machine translation by learning to map between languages and generate translations that are both accurate and fluent. They can be fine-tuned to work with different language pairs, providing valuable tools for breaking language barriers in communication.
Sentiment analysis: LLMs can be used to classify text based on sentiment, such as positive, negative, or neutral. This application is useful for understanding customer opinions, analyzing product reviews, or monitoring social media trends.
Text summarization: LLMs can generate concise summaries of long articles or documents while maintaining key information and context. This application can aid in information retrieval, content curation, and making large volumes of text more accessible.
Question-answering systems: LLMs can understand and extract information from text to provide answers to specific questions. This capability has been used in developing virtual assistants, customer support chatbots, and knowledge base search systems.
Text generation and content creation: LLMs can generate contextually relevant and coherent text, making them valuable tools for content generation in fields like journalism, marketing, and creative writing.
Text classification and topic modeling: LLMs can classify documents into categories based on their content or automatically extract topics from large text collections. These applications are useful in document organization, search, and recommendation systems.
Named entity recognition and relationship extraction: LLMs can identify and categorize entities in text, such as people, organizations, or locations. They can also extract relationships between these entities, enabling applications like knowledge graph construction, information extraction, and data mining.
Paraphrasing and text simplification: LLMs can be used to rephrase text while preserving the original meaning, making it easier to understand or adapting it for specific audiences.
Code generation and programming assistance: LLMs can be fine-tuned to understand programming languages, providing assistance in tasks like code generation, code completion, and bug detection.
Conversational AI: LLMs are widely used in building chatbots and virtual assistants capable of understanding natural language and generating human-like responses. These conversational agents can be employed in various settings, such as customer support, personal assistance, or mental health support.
Language modeling and grammar correction: LLMs can be used to predict missing words or phrases in text, enabling applications like autocomplete, spell-checking, and grammar correction.
These applications are just a glimpse of the potential uses of LLMs in various domains. As the field of natural language processing continues to advance, we can expect the development of even more innovative applications that leverage the capabilities of LLMs to address a wide range of challenges and problems.
Surrounding Issues#
Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks. However, their development and widespread use also bring up several surrounding issues that need to be carefully considered. Some of the key issues related to LLMs include:
Resource requirements: Training LLMs requires vast amounts of computational resources, which can be both expensive and energy-intensive. This high resource demand can lead to centralization of AI research, limiting access to cutting-edge models for smaller organizations and researchers.
Data biases: LLMs are trained on massive datasets, which may contain biases present in the source data. These biases can result in unintended consequences, such as the model generating biased or offensive outputs. Addressing these biases is an ongoing challenge that involves careful dataset curation and model evaluation to mitigate potential harm.
Ethical concerns: LLMs can generate content that is indistinguishable from human-written text, raising concerns about their potential misuse in generating disinformation, fake news, or other malicious content. Ensuring responsible use of LLMs is essential for minimizing the risks associated with their capabilities.
Model interpretability: Understanding the decision-making process of LLMs can be challenging due to their complex architecture and the vast number of parameters involved. Improving interpretability and explainability of LLMs is important for ensuring trust in their predictions and facilitating their adoption in critical applications.
Deployment challenges: Deploying LLMs in real-world applications often requires significant computational resources and expertise. Simplifying the deployment process and making these models more accessible to a wider audience are ongoing challenges in the field.
Fairness and inclusivity: Ensuring that LLMs are fair and inclusive of various languages, dialects, and cultural perspectives is essential for building AI systems that work for everyone. Addressing issues related to the representation and treatment of minority languages and dialects in LLMs is a critical aspect of developing more equitable AI systems.
Environmental impact: The energy consumption associated with training LLMs has raised concerns about their environmental impact. Developing more energy-efficient training methods and promoting the use of renewable energy sources can help mitigate the environmental footprint of LLMs.
Legal and regulatory implications: The capabilities of LLMs and their potential applications raise legal and regulatory questions, such as intellectual property rights, content moderation, and liability for generated outputs. Developing legal and regulatory frameworks that address these challenges is crucial for fostering responsible innovation in the field of AI.
Addressing these surrounding issues requires a collective effort from researchers, developers, policymakers, and other stakeholders in the AI community. By acknowledging and addressing these challenges, we can work towards the responsible development and use of LLMs in a way that maximizes their potential benefits while minimizing potential harm.
Emergent abilities of large language models#
Wei et al. [2022] defined an emergent ability as an ability that is “not present in small models but is present in large models.”
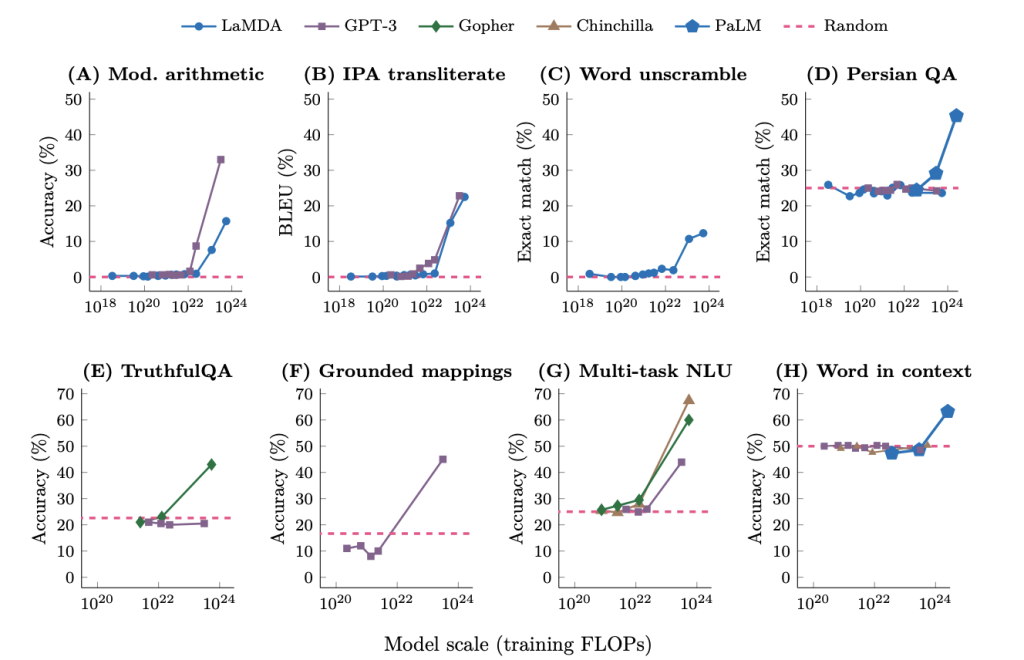
Fig. 89 Eight examples of emergence in the few-shot prompting setting.#
Emergence in large language models refers to abilities not present in small models but found in larger ones. Over 100 examples of emergent abilities have been discovered in models like GPT-3, Chinchilla, and PaLM. These abilities can be classified into two categories: emergent few-shot prompted tasks and emergent prompting strategies.
Emergent few-shot prompted tasks are tasks where small models perform at random chance, while large models perform well above-random. Sources for these tasks include BIG-Bench, the Massive Multitask Benchmark, and several papers showcasing individual tasks as emergent abilities.
Emergent prompting strategies are general prompting strategies that work only for sufficiently large-scale language models. Examples include instruction-following, scratchpad, chain-of-thought prompting, and leveraging explanations in prompting.
Promising future research directions include improving model architectures, enhancing data quality and quantity, optimizing prompting, exploring frontier tasks, and understanding why emergent abilities occur and if they can be predicted.
BIG-Bench (67 tasks):#
GPT-3 13B (2 tasks): hindu knowledge, modified arithmetic
GPT-3 175B (15 tasks): analytic entailment, codenames, etc.
LaMDA 137B (8 tasks): gender inclusive sentences german, repeat copy logic, etc.
PaLM 8B (3 tasks): auto debugging, sufficient information, parsinlu reading comprehension
PaLM 64B (14 tasks): anachronisms, ascii word recognition, etc.
PaLM 540B (25 tasks): analogical similarity, causal judgment, etc.
MMLU (51 tasks; see Chinchilla paper for results):#
Chinchilla 7B (7 tasks): Professional Medicine, High School Statistics, etc.
Chinchilla 70B (44 tasks): International Law, Human Aging, etc.
Individual emergent tasks from papers:#
GPT-3 paper: 3 digit addition/subtraction (GPT-3 13B), 4-5 digit addition/substraction (GPT-3 175B), leveraging few-shot examples for word denoising (GPT-3 13B)
Gopher paper: Toxicity classification (Gopher 7.1B), TruthfulQA (Gopher 280B)
Patel & Pavlick: grounded conceptual mappings (GPT-3 175B)
PaLM paper: Word in Context benchmark (PaLM 540B)