GloVe#
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. It is based on the co-occurrence matrix of words from a corpus.
GloVe stands for Global Vectors for Word Representation. It was introduced by [Pennington et al., 2014] in 2014.
Improvement over word2vec#
Word2vec uses a window-based approach, in which it only considers the local context of a word. This means that it does not consider the global context of a word.
GloVe uses a global context of a word in addition to the local context. This means that it can capture the meaning of a word better than word2vec.
Co-occurrence matrix#
What are the global contexts of a word? The global contexts of a word are the words that co-occur with it in a corpus.
For example, we have the following sentences:
Document 1: “All that glitters is not gold.”
Document 2: “ All is well that ends well.”
Then, with a window size of 1, the co-occurrence matrix of the words in the corpus is:
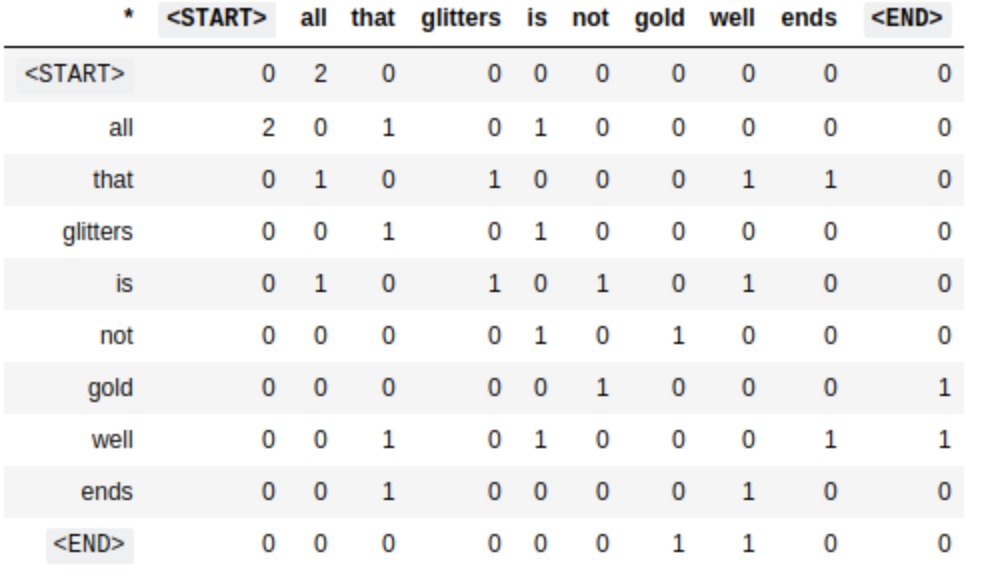
The rows and columns represent the words in the corpus.
<START>and<END>are special tokens that represent the start and end of a sentence.Since
thatandisoccur only once in the window ofglitters, the value of (that,glitters) and (is,glitters) is 1.
Training GloVe#
Glove model is a weighted least squares regression model, where the weights are the word vectors. The objective function is the sum of squared errors between the co-occurrence matrix and the dot product of the word vectors.
where \(X_{ij}\) is the co-occurrence matrix, \(\mathbf{u}_i\) is the word vector of the \(i\) th word, and \(\mathbf{v}_j\) is the word vector of the \(j\) th word. The function \(f\) is a weighting function that is used to downweight the common words.
GloVe vs word2vec#
GloVe is a global model, while word2vec is a local model.
GloVe ouputperforms word2vec on word analogy, word similarity, and Named Entity Recognition (NER) tasks.
If the nature of the problem is similar to the above tasks, then GloVe is a better choice than word2vec.
Since it uses a global context, GloVe is better at capturing the meaning of rare words even on small datasets.
GloVe is slower than word2vec.
Using GloVe#
GloVe is available to download from the Stanford NLP website.