DALL·E 2#

Fig. 162 DALL·E 2#
CLIP#
Blog post: https://openai.com/blog/clip/
Code: openai/CLIP (does not cover the training part)
Models: Available (on Apr 22, 2022, the last and the best ViT-L/14@336px model was published)
Alternative code: mlfoundations/open_clip (with training)
Alternative models (Multilingual): FreddeFrallan/Multilingual-CLIP
CLIP, which stands for Contrastive Language-Image Pre-Training, was initially developed as an auxiliary model to help rank the results generated by DALL·E. The concept behind CLIP is to train a contrastive model using a massive dataset of image-text pairs collected from the internet, consisting of around 400 million pairs. The purpose of a contrastive model is to assign high scores (indicating similarity) to images and texts that belong together, while giving low scores to mismatched images and texts. This makes it easier to identify and rank relevant results based on the level of similarity between images and their corresponding text descriptions.
CLIP: technical details#
The CLIP model is made up of two encoders: one for text and another for images. These encoders generate embeddings, which are multidimensional vector representations of objects, such as 512-byte vectors for each input. To calculate the similarity between the text and image embeddings, the dot product of the two vectors is computed.
Since the embeddings are normalized, this process results in cosine similarity. Cosine similarity values range from -1 to 1, where a value close to 1 indicates that the vectors point in the same direction (and thus have a small angle between them), 0 signifies orthogonal vectors, and -1 means the vectors are pointing in opposite directions.
The goal of the model is to maximize the similarity score for image-text pairs that belong together and minimize the score for mismatched pairs. This helps in identifying and ranking relevant results based on the similarity between images and their associated text descriptions.
Contrastive pre-training#
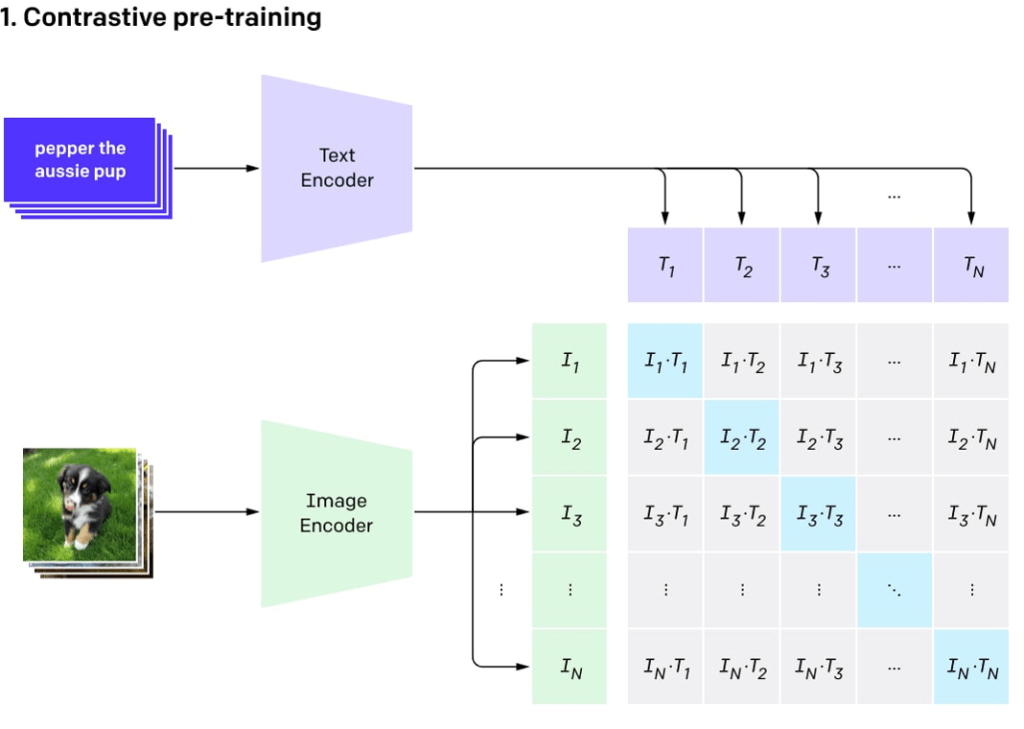
Fig. 163 Contrastive pre-training#
Contrastive pre-training is a machine learning technique used to train models by teaching them to distinguish between related and unrelated inputs. The goal is to improve the model’s understanding and representation of data by comparing different data elements and identifying their similarities and differences.
In this approach, the model is presented with pairs of data elements, such as images and text. For each pair, the model must learn to recognize when the elements are related (positive pairs) and when they are not (negative pairs). By adjusting its internal representation of the data, the model learns to generate high similarity scores for positive pairs and low similarity scores for negative pairs.
Contrastive pre-training can be applied to various types of data, such as images, text, and audio. The technique has been particularly useful for training models that work with multiple modalities, like image-text models, as it enables them to better understand the relationships between different data types. This leads to improved performance in tasks such as image recognition, natural language understanding, and information retrieval.
CLIP image encoders#
The CLIP model utilizes nine different image encoders, which include five convolutional encoders and four transformer encoders. The convolutional encoders are based on ResNet and EfficientNet-like architectures, such as ResNet-50, ResNet-101, and three EfficientNet models called RN50x4, RN50x16, and RN50x64. Higher numbers in the model names typically indicate better performance.
The transformer encoders are called Vision Transformers (ViT), and they come in four variations: ViT-B/32, ViT-B/16, ViT-L/14, and ViT-L/14@336. The first three transformers are trained on images with a resolution of 224x224 pixels, while the last one, ViT-L/14@336, is fine-tuned on images with a higher resolution of 336x336 pixels. These diverse encoders contribute to the model’s ability to analyze and understand images effectively.
CLIP text encoders#
The text encoder in the CLIP model is a standard transformer encoder with masked attention. It is composed of 12 layers, each containing 8 attention heads, and has a total of 63 million parameters. However, the attention span is limited to only 76 tokens, which is much shorter compared to GPT-3’s 2048 tokens or a standard BERT model’s 512 tokens.
Due to this constraint, the text encoder is designed to handle relatively short texts, and it cannot process large paragraphs effectively. DALL·E 2, which primarily utilizes the same CLIP model, is likely to have the same limitation. This means that both models are better suited for working with brief text inputs rather than lengthy passages.
CLIP applications#
The CLIP model can be employed in various ways, such as ranking text-image pairs, which was its original purpose in DALL·E. This helps score multiple results and select the best one. Additionally, you can use the features extracted from CLIP to build custom classifiers tailored to specific tasks.
Another interesting application of CLIP is zero-shot classification, which allows the model to classify inputs into categories it has never been explicitly trained on. This makes it highly flexible, as you can adjust the class labels without needing to retrain the model. Overall, CLIP offers a versatile approach to handling text-image relationships and can be adapted for different use cases.
Zero-shot classification with CLIP#
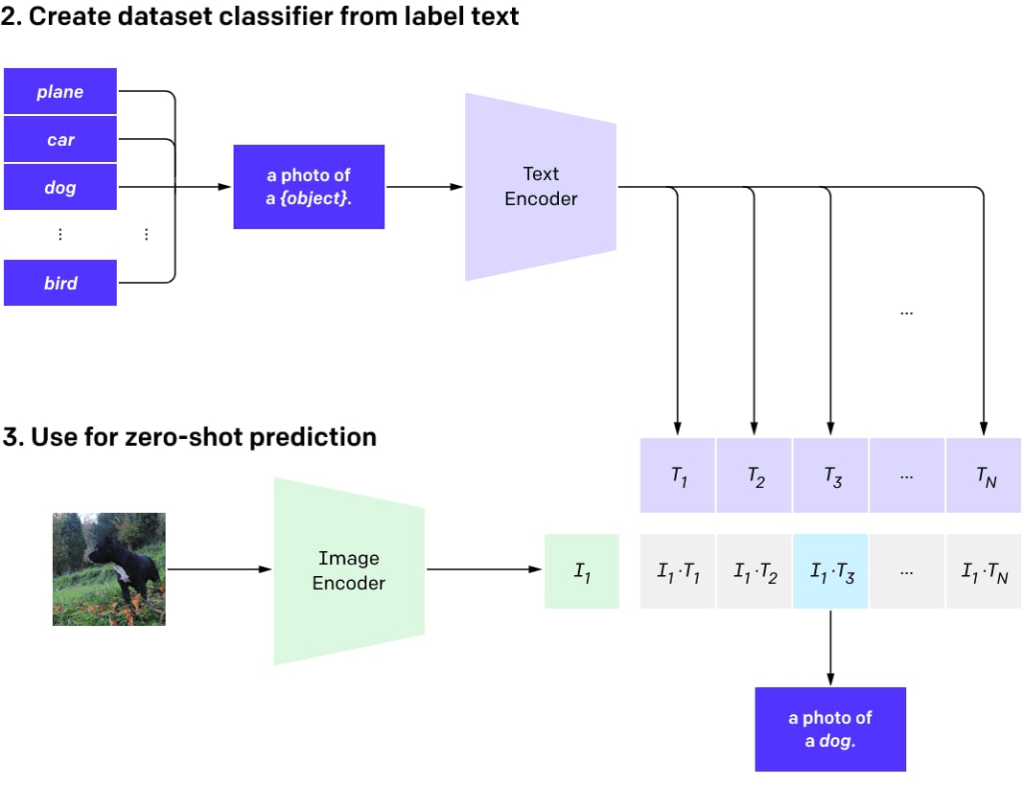
Fig. 164 Zero-shot classification with CLIP#
Zero-shot classification with CLIP refers to the ability of the model to classify inputs into categories it hasn’t been explicitly trained on. This is particularly useful when dealing with new or unforeseen classes, as it enables the model to adapt without needing to be retrained.
The CLIP model is designed to understand the relationships between images and text. When applying it to zero-shot classification, the model uses its knowledge of these relationships to determine which category is most appropriate for a given input, even if it has never encountered that specific category before.
In practice, this involves providing the model with a set of potential category labels and asking it to rank these labels based on their relevance to the input. The model then assigns the input to the category with the highest relevance score, effectively classifying the input without any prior knowledge of that category.
The zero-shot classification capability of CLIP makes it a flexible and versatile tool for handling a wide range of classification tasks, especially when dealing with new or changing categories.
CLIP prompt engineering: CLIPDraw#
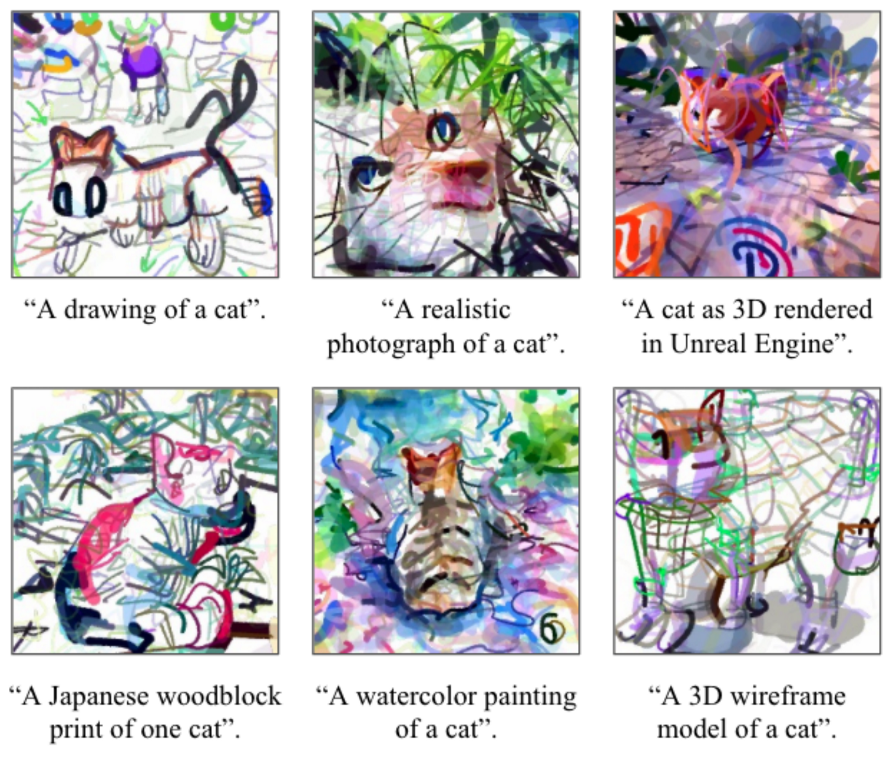
Fig. 165 CLIPDraw#
CLIP prompt engineering with CLIPDraw is a technique that allows you to generate images by crafting effective text prompts. This approach takes advantage of the CLIP model’s understanding of image-text relationships and offers a flexible way to create new images based on textual descriptions.
CLIPDraw generation procedure

Fig. 166 CLIPDraw generation procedure#
CLIP prompt engineering: VQGAN-CLIP#

Fig. 167 VQGAN-CLIP#
VQGAN-CLIP is a popular application that combines the CLIP model with a Vector Quantized Generative Adversarial Network (VQGAN) for generating high-quality images based on textual descriptions.
In VQGAN-CLIP, the text prompt serves as the guiding principle for the image generation process. By providing a well-crafted prompt, you can steer the model to generate images that closely match your intended vision. The key is to create prompts that are clear, concise, and accurately describe the visual elements you wish to see in the generated image.
The process works by using the CLIP model to guide the VQGAN during image synthesis. The CLIP model understands the relationships between text and images and helps evaluate how well the generated image matches the provided prompt. On the other hand, the VQGAN is responsible for producing high-quality images based on this guidance.
As the VQGAN generates images, the CLIP model assesses their similarity to the text prompt and provides feedback to refine the output further. This iterative process continues until the generated image closely aligns with the given text description.
VQGAN-CLIP generation procedure
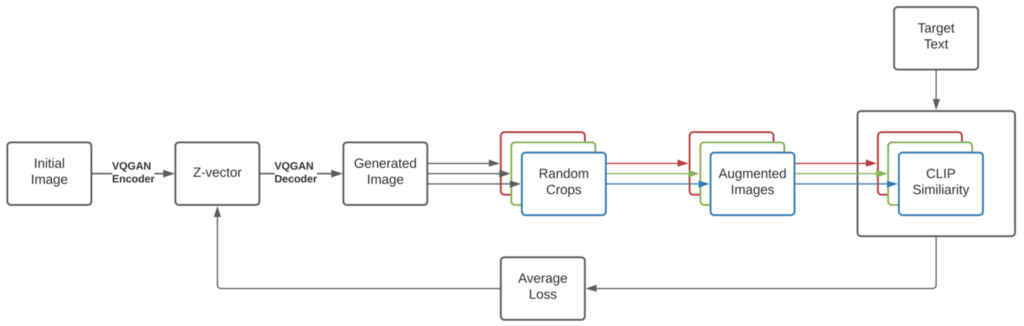
Fig. 168 VQGAN-CLIP generation procedure#
GLIDE#
Blog post: Strangely enough, OpenAI didn’t make a post on it
Code: openai/glide-text2im
Models: Available, but only a small model (300M instead of 3.5B parameters) trained on a filtered dataset
GLIDE, an acronym for Guided Language to Image Diffusion for Generation and Editing, is an image generation model developed by OpenAI. This model can create images with a resolution of 256x256 pixels based on text guidance.
Although the GLIDE model has 3.5 billion parameters, the correct number appears to be 5 billion, considering there is a separate upsampling model with an additional 1.5 billion parameters. Despite having fewer parameters than the 12 billion-parameter DALL·E model, human evaluators prefer GLIDE, and it also outperforms DALL·E in terms of the FID score, which measures image quality.
Moreover, GLIDE models can be fine-tuned for image inpainting tasks, enabling powerful text-driven image editing capabilities. Overall, GLIDE offers an advanced and versatile approach to generating and editing images using textual descriptions.
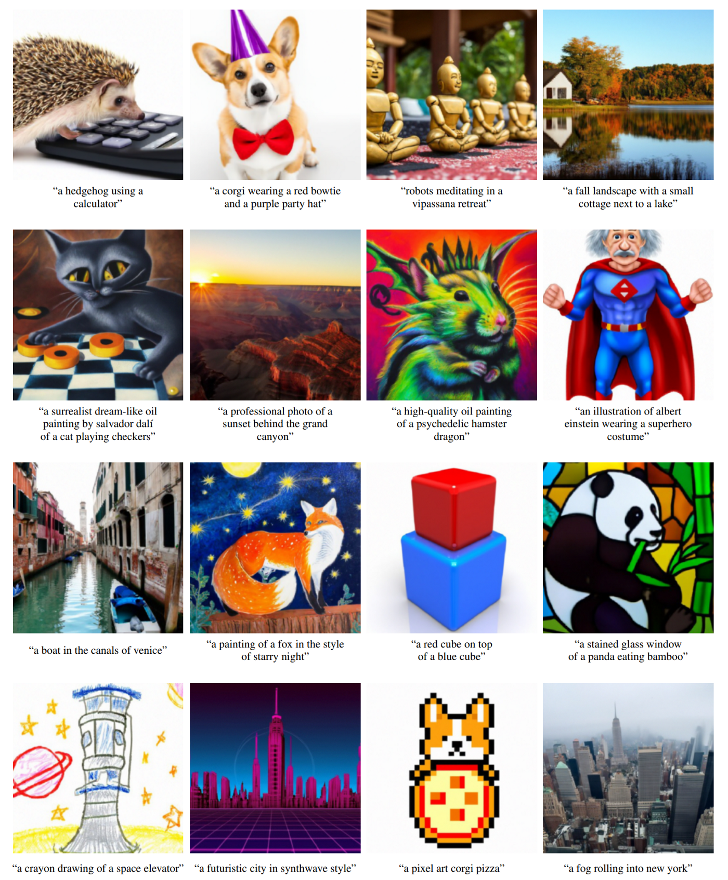
Fig. 169 GLIDE examples#

Fig. 170 Text-conditional image inpainting#
Diffusion model#

Fig. 171 Diffusion model#
GLIDE is similar to a type of model known as a diffusion model. In diffusion models, random noise is introduced to input data through a series of diffusion steps. The model then learns to reverse this process, effectively reconstructing images from the noise. This approach allows diffusion models, like GLIDE, to generate images by gradually refining and removing the random noise introduced earlier in the process.
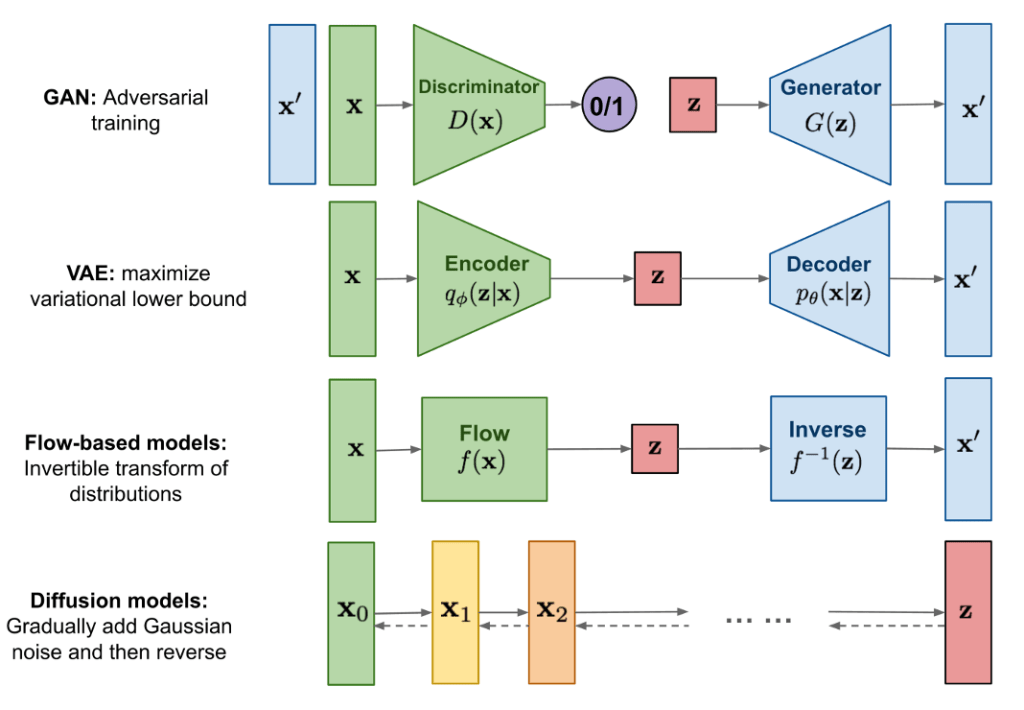
Fig. 172 Diffusion models compared to the other classes of generative models#
GLIDE technical details#
The creators of GLIDE first trained a 3.5 billion-parameter diffusion model that utilizes a text encoder to condition image generation based on natural language descriptions. They then compared two techniques for guiding diffusion models towards text prompts: CLIP guidance and classifier-free guidance.
Classifier guidance enables diffusion models to condition on a classifier’s labels, using gradients from the classifier to guide the image generation towards a specific label. On the other hand, classifier-free guidance doesn’t require a separate classifier model to be trained. This approach interpolates between predictions from a diffusion model with and without labels.
Classifier-free guidance offers two benefits. First, it allows a single model to use its own knowledge during guidance, instead of depending on a separate (and sometimes smaller) classification model. Second, it simplifies guidance when working with information that is challenging to predict with a classifier, such as text.
In CLIP guidance, the classifier is replaced by a CLIP model. This method uses the gradient of the dot product between image and text encodings with respect to the image. The text-conditioned diffusion model is an augmented ADM model architecture that predicts an image for the next diffusion step based on a noised image (xₜ) and the corresponding text caption ©.
GLIDE technical details: visual part
The visual component of the GLIDE model is based on a modified U-Net architecture. The U-Net model comprises a stack of residual layers with down-sampling convolutions, followed by another stack of residual layers with up-sampling convolutions. Skip connections are used to link layers with the same spatial dimensions. Various modifications have been made to the original U-Net architecture in terms of width, depth, and other aspects.
Global attention layers, featuring multiple attention heads, have been added at the 8x8, 16x16, and 32x32 resolutions. Additionally, a projection of the timestep embedding is incorporated into each residual block.
For classifier guidance, the classifier architecture is based on the down-sampling section of the U-Net model, with an attention pool added at the 8x8 layer to generate the final output. This adaptation of the U-Net architecture contributes to the performance and capabilities of the GLIDE model.
The original U-Net architecture
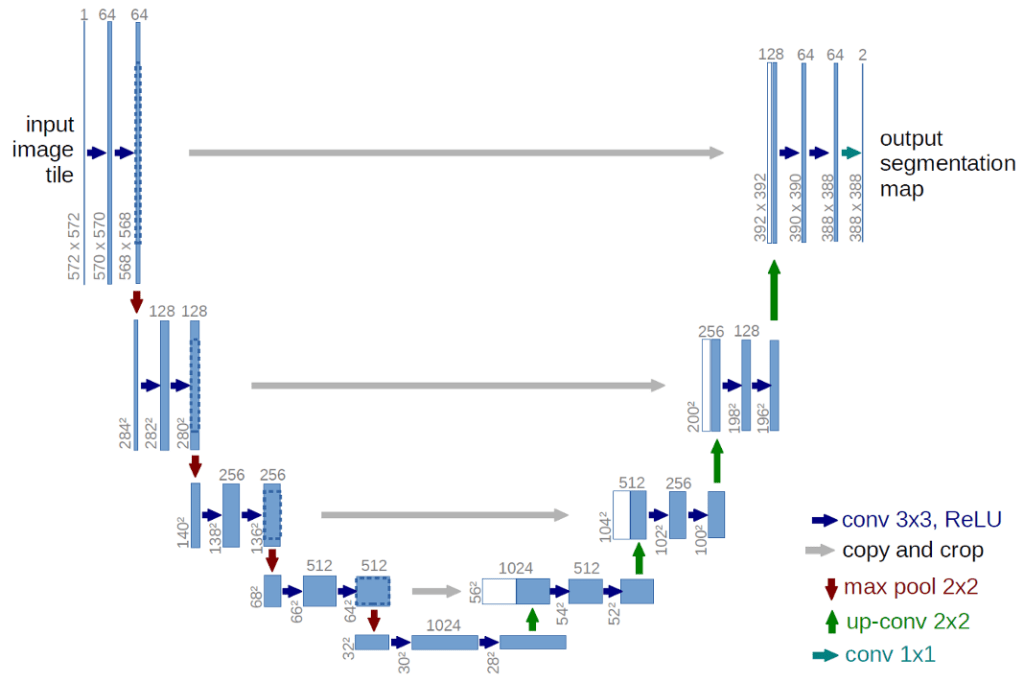
Fig. 173 The original U-Net architecture#
GLIDE technical details: text part
In the GLIDE model, text is encoded into a sequence of K tokens (the maximum attention span is unspecified) and processed through a transformer model. The output of this transformer is utilized in two ways:
The final token embedding replaces the class embedding in the ADM model.
The last layer of token embeddings (a sequence of K feature vectors) is projected to the dimensionality of each attention layer in the ADM model and then concatenated to the attention context at each layer.
The text transformer comprises 24 residual blocks with a width of 2048, resulting in approximately 1.2 billion parameters. The visual part of the model, designed for 64x64 resolution, consists of 2.3 billion parameters.
In addition to the 3.5 billion-parameter text-conditional diffusion model, the authors developed a 1.5 billion-parameter text-conditional upsampling diffusion model to increase the resolution to 256x256 (a concept also used in DALL·E). The upsampling model is conditioned on text in the same manner as the base model but employs a smaller text encoder with a width of 1024 instead of 2048.
For CLIP guidance, a noised 64x64 ViT-L CLIP model was also trained. GLIDE was trained on the same dataset as DALL·E, and the total training compute is roughly equal to that used for DALL·E.
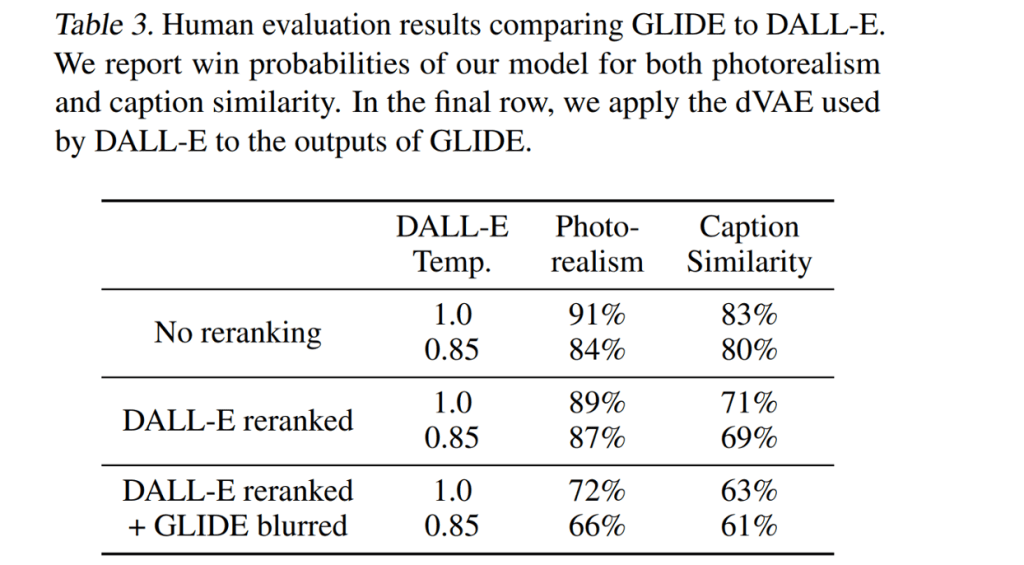
Fig. 174 GLIDE is preferred by the human evaluators#
GLIDE finetuning#
The GLIDE model was fine-tuned to enable unconditional image generation. The training procedure is similar to pre-training, but 20% of text token sequences are replaced with an empty sequence. As a result, the model can generate images both with and without text prompts.
Furthermore, GLIDE was explicitly fine-tuned for inpainting tasks. During this process, random regions of training examples are erased, and the remaining parts are fed into the model along with a mask channel to provide additional conditioning information.
GLIDE can be used iteratively to create complex scenes by first generating an image using a zero-shot approach and then applying a series of inpainting edits. For example, an image could be generated with the prompt “a cozy living room.” Inpainting masks are then applied, along with follow-up text prompts, to add a painting to the wall, a coffee table, a vase of flowers on the coffee table, and finally to move the wall up to the couch. This iterative process allows GLIDE to produce detailed and customized images based on user input.

Fig. 175 GLIDE inpainting#
DALL·E 2/unCLIP#
Blog post: https://openai.com/dall-e-2/
Code: Not available
Models: Not available
Code (unofficial): lucidrains/DALLE2-pytorch

Fig. 176 DALL·E 1 vs. DALL·E 2#
OpenAI unveiled the DALL·E 2 system on April 6th, 2022, which offers significant improvements over the original DALL·E. The new system can generate images at a 4x higher resolution, reaching 1024x1024 pixels, compared to the original DALL·E and GLIDE models.
The model powering DALL·E 2 is called unCLIP. Although humans slightly favor GLIDE over unCLIP in terms of photorealism, the difference is minimal. However, unCLIP is highly preferred over GLIDE in terms of image diversity, which is one of its key advantages. This updated model offers both high-resolution image generation and a diverse range of creative outputs.

Fig. 177 DALL·E 2 can combine concepts, attributes, and styles#

Fig. 178 Image editing based on text guidance#

Fig. 179 Generating variations of an image#

Fig. 180 Some problems with DALL·E 2#

Fig. 181 unCLIP also struggles at producing coherent text#

Fig. 182 Producing details in complex scenes#
DALL·E 2 technical details#
DALL·E 2 is a smart combination of the CLIP and GLIDE models, and its full text-conditional image generation architecture is internally referred to as unCLIP in the paper. This is because it generates images by inverting the CLIP image encoder.
First, the CLIP model is trained separately. Next, the CLIP text encoder creates an embedding for the input text, or caption. Following this, a unique prior model generates an image embedding based on the text embedding. Finally, a diffusion decoder creates an image using the image embedding.
The decoder’s primary function is to convert image embeddings back into images, effectively linking the text prompt to the final visual output.
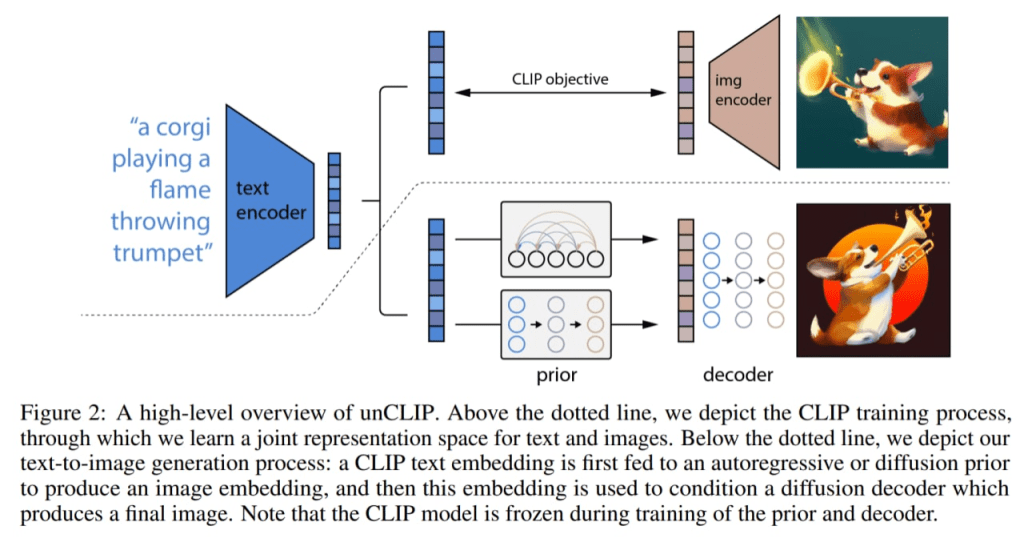
Fig. 183 A high-level overview of DALL·E 2#
DALL·E 2 technical details: encoders#
In the DALL·E 2 system, the CLIP model employs a ViT-H/16 image encoder designed for 256x256 resolution images. It has a width of 1280 and consists of 32 Transformer blocks, making it deeper than the largest ViT-L model from the original CLIP work. The text encoder used in this system is a Transformer with a causal attention mask. It has a width of 1024 and is made up of 24 Transformer blocks, which is double the number of blocks in the original CLIP model. These enhancements contribute to the improved performance of DALL·E 2 compared to its predecessor.
DALL·E 2 technical details: decoders#
The diffusion decoder in DALL·E 2 is a modified GLIDE model with 3.5 billion parameters. CLIP image embeddings are projected and combined with the existing timestep embedding, and also projected into four extra tokens of context, which are then added to the output sequence from the GLIDE text encoder. The original GLIDE text conditioning pathway is retained, as it could potentially help the diffusion model learn aspects of natural language that CLIP might not capture, though it has limited impact. During training, CLIP embeddings are randomly set to zero 10% of the time, and the text caption is randomly dropped 50% of the time.
The decoder first generates a 64x64 pixel image. Next, two upsampling diffusion models create 256x256 and 1024x1024 images, with the former having 700 million parameters and the latter 300 million parameters. To enhance upsampling robustness, conditioning images are slightly corrupted during training. Gaussian blur is used for the first upsampling stage, while the second stage uses a more diverse BSR degradation, which includes JPEG compression artifacts, camera sensor noise, bilinear and bicubic interpolations, and Gaussian noise. The models are trained on random image crops that are one-fourth the target size, and text conditioning is not used for the upsampling models.
DALL·E 2 technical details: the prior#
The prior model in DALL·E 2 generates image embeddings from text descriptions using either an Autoregressive (AR) prior or a Diffusion prior, both with 1 billion parameters. Besides the caption, the prior model can be conditioned on the CLIP text embedding. To enhance sample quality, the authors use classifier-free guidance for both AR and diffusion priors by randomly dropping the text conditioning information 10% of the time during training.
For the AR prior, the CLIP image embedding’s dimensionality is reduced using Principal Component Analysis (PCA). A sequence of discrete codes is predicted autoregressively, conditioned on the caption and the CLIP text embedding. Additionally, a token indicating the (quantized) dot product between the text and image embeddings is included, allowing the model to condition on a higher dot product for better image-caption alignment. A Transformer model with a causal attention mask is used for prediction.
For the Diffusion prior, a decoder-only Transformer with a causal attention mask is trained on a sequence that includes the encoded text, CLIP text embedding, diffusion timestep, noised CLIP image embedding, and a final embedding used to predict the unnoised CLIP image embedding. Unlike the AR prior, a dot product is not used for conditioning. Instead, two samples of an image embedding are generated during sampling, and the one with a higher dot product with the text embedding is selected. The Diffusion prior outperforms the AR prior in terms of model size, reduced training compute, and pairwise comparisons against GLIDE.
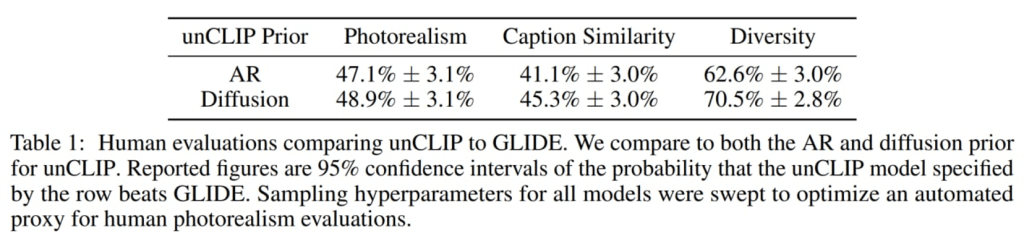
Fig. 184 AR vs Diffusion prior#

Fig. 185 Using different conditioning signals#
DALL·E 2 technical details: training#
During the training process, the authors used different datasets for the encoder and the generative components. For training the encoder, they sampled from both the CLIP and DALL-E datasets, which consist of approximately 650 million images in total. However, for training the decoder, upsamplers, and prior, they relied solely on the DALL-E dataset, comprising around 250 million images. This decision was made because incorporating the noisier CLIP dataset while training the generative components negatively affected the sample quality in their initial evaluations.
The total model size appears to be approximately 6.5 billion parameters, which includes: 632 million parameters for the CLIP ViT-H/16 image encoder, 340 million parameters for the CLIP text encoder, 1 billion parameters for the Diffusion prior, 3.5 billion parameters for the diffusion decoder, and 1 billion parameters for the two diffusion upsamplers.

Fig. 186 unCLIP applications#
Each image x can be encoded into a bipartite latent representation (zi, xT), which is sufficient for the decoder to produce an accurate reconstruction. The latent zi is a CLIP image embedding that describes the aspects of the image recognized by CLIP. The latent xT is obtained by applying the DDIM (denoising diffusion implicit model) inversion to x using the decoder while conditioning on zi. In other words, it serves as the starting noise for the diffusion process when generating the image x (or equivalently x0).
Three interesting kinds of manipulations can be performed:
Creating image variations: By sampling in the decoder using DDIM with η > 0, you can create variations for a given bipartite latent representation (zi, xT). With η = 0, the decoder becomes deterministic and reconstructs the given image x. The larger the η parameter, the greater the variations, revealing what information was captured in the CLIP image embedding and present in all samples.
Interpolating between images x1 and x2: To do this, take the CLIP image embeddings zi1 and zi2, and apply slerp (Spherical Linear Interpolation) to obtain intermediate CLIP image representations. For the corresponding intermediate DDIM latent xTi, you have two options:
Interpolate between xT1 and xT2 with slerp.
Fix the DDIM latent to a randomly-sampled value for all interpolates in the trajectory, allowing the generation of an infinite number of trajectories. The following images were generated using the second option.
Language-guided image manipulations or text diffs: To modify an image to reflect a new text description y, first obtain its CLIP text embedding zt and the CLIP text embedding zt0 of a caption describing the current image (which could be a dummy caption like “a photo” or an empty caption). Then, compute a text diff vector zd = norm(zt − zt0). Next, rotate between the image CLIP embedding zi and the text diff vector zd using slerp and generate images with the fixed base DDIM noise xT throughout the entire trajectory.
Examples of manipulations in “concept space” for text include “woman” + “king” - “man”. Arithmetic can also be performed using both text and images, such as (image of Victorian house) + “a modern house” - “a Victorian house”.

Fig. 187 Creating image variations#

Fig. 188 Interpolating between images#

Fig. 189 Exploring text diffs#

Fig. 190 Typographic attacks#
The struggles of unCLIP#
UnCLIP faces several challenges, including attribute binding, text generation, and detail representation in complex scenes. The first two issues likely stem from the properties of CLIP embeddings.
Attribute binding problem: This issue may occur because CLIP embeddings do not explicitly bind attributes to objects, causing the decoder to mix up attributes and objects when generating an image.
Text generation problem: This challenge might arise because CLIP embeddings do not accurately encode the spelling information of rendered text.
Low details problem: This problem could be due to the decoder hierarchy, which generates an image at a base resolution of 64x64 pixels and then upsamples it. Increasing the base resolution may resolve this issue but would come at the cost of additional training and inference computation.

Fig. 191 Binding problems#